
- Спроба абыходу JavaScript Сайт без Rendering
- Як Crawl JavaScript вэб-сайтаў з Sitebulb
- Што гэта рэндэру Тайм-аўт?
- Прыклад візуалізацыі тайм-аўту
- Рэкамендуецца рэндэру Тайм-аўт
- Пабочныя эфекты поўзаць з JavaScript
- Як выявіць JavaScript сайты
- кліент Briefing
- спроба кролем
- Кіраўніцтва па правядзенні інспекцыі
- далейшае чытанне
Наша команда-партнер Artmisto
Сканіраванне вэб-сайтаў у 2018 годзе гэта не зусім так проста, як гэта было некалькі гадоў таму, і гэта ў асноўным за кошт росту выкарыстання фреймворков, такіх як вуглавыя, React і Meteor.
Традыцыйна гусенічны будзе працаваць шляхам вымання дадзеных з статычнага HTML кода, і да нядаўняга часу, большасць вэб-сайтаў вы сутыкнецеся можа сканіравацца ў гэтай манеры.
Аднак, калі вы спрабуеце сканаваць вэб-сайт пабудаваны з Кутнім такім чынам, вы не атрымаеце вельмі далёка (у літаральным сэнсе). Для таго, каб «бачыць» у HTML вэб-старонкі (а змест і спасылкі ўнутры яго), то сканер павінен апрацоўваць увесь код на старонцы і на самай справе аказваюць змест.
Google апрацоўвае гэта ў 2-фазным падыходзе , Першапачаткова яны поўзаюць і індэкс, заснаваны на статычным HTML ( «першай хвалі» індэксацыі). Затым, калі ў іх ёсць рэсурсы для таго, каб зрабіць старонку, яны выконваюць другую хвалю індэксацыі на аснове аказанай HTML.
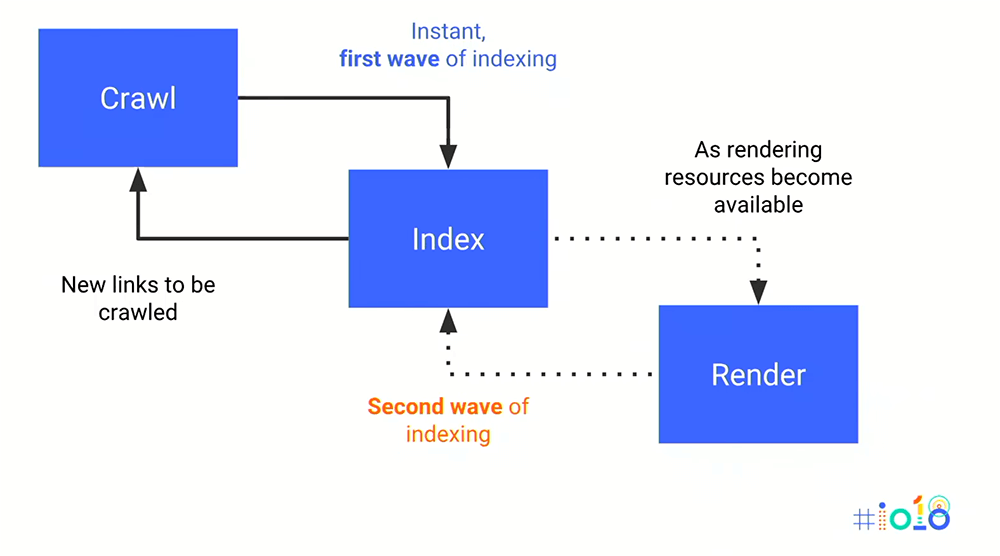
Спроба абыходу JavaScript Сайт без Rendering
Мы першыя збіраемся даследаваць тое, што гэтая першая хваля індэксацыі будзе выглядаць на вэб-сайт, пабудаваны ў рамках JavaScript.
Мой сябар працуе сайт пабудаваны ў Backbone, і яго вэб-сайт забяспечвае выдатны прыклад, каб убачыць, што адбываецца.
разглядаць на старонцы прадукту для іх самага папулярнага прадукту. З Chrome -> Праверце, мы можам убачыць h1 на старонцы:
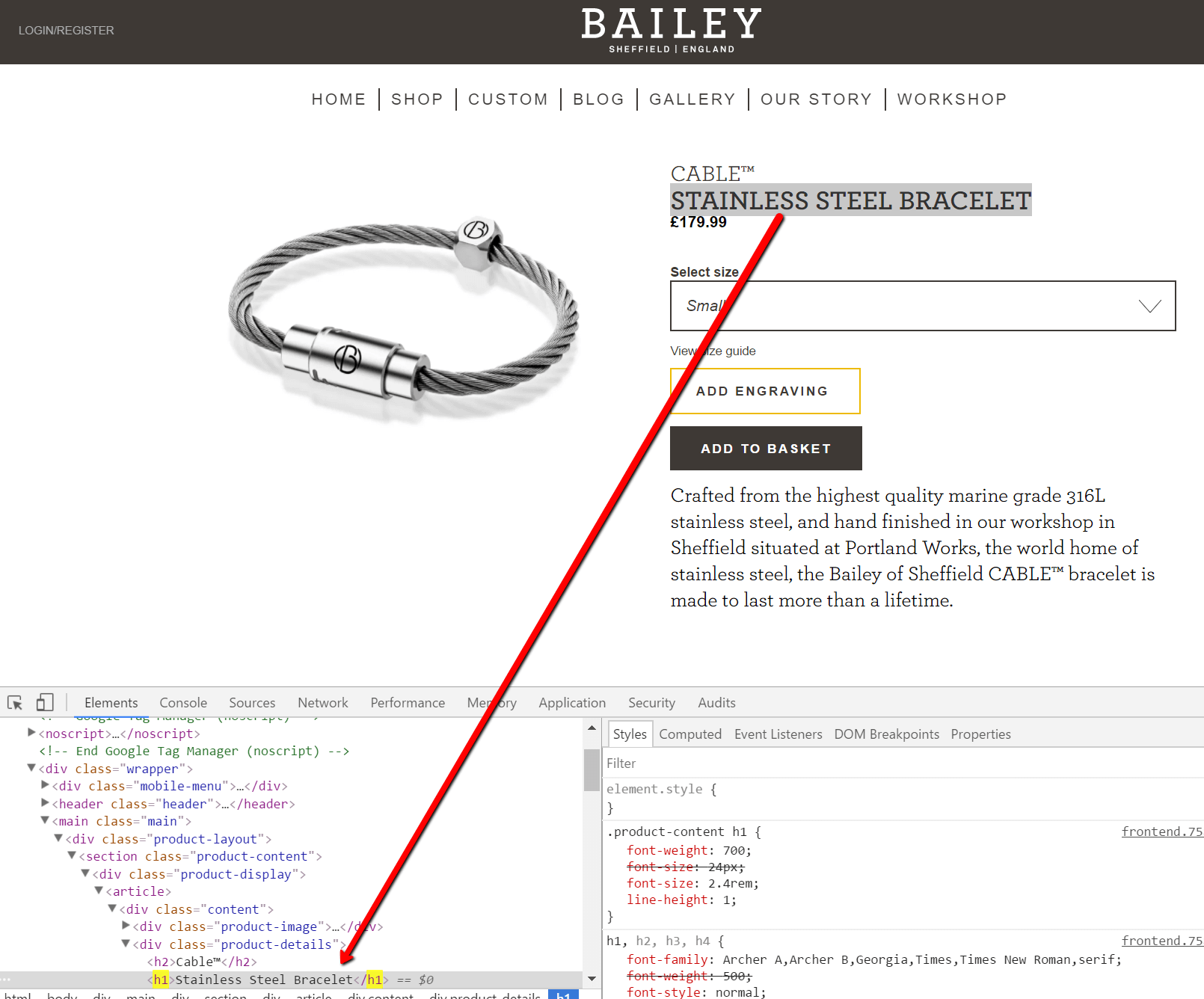
Аднак, калі мы проста паглядзець-крыніца на гэтай старонцы, няма h1 на ўвазе:
Пракрутка далей ўніз старонкі выгляд крыніцы будзе проста паказаць вам кучу сцэнарыяў і некаторы рэзервовы тэкст. Вы проста не можаце ўбачыць мяса і косткі старонкі - выява прадукту, апісанне, тэхнічныя спецыфікацыі, відэа, а самае галоўнае, спасылкі на іншыя старонкі.
Так што, калі вы спрабавалі паўзці гэты сайт у традыцыйнай манеры (з дапамогай «HTML Crawler»), усе дадзеныя гусенічны звычайна здабываюць у асноўным нябачным для яго. І гэта тое, што вы атрымаеце:
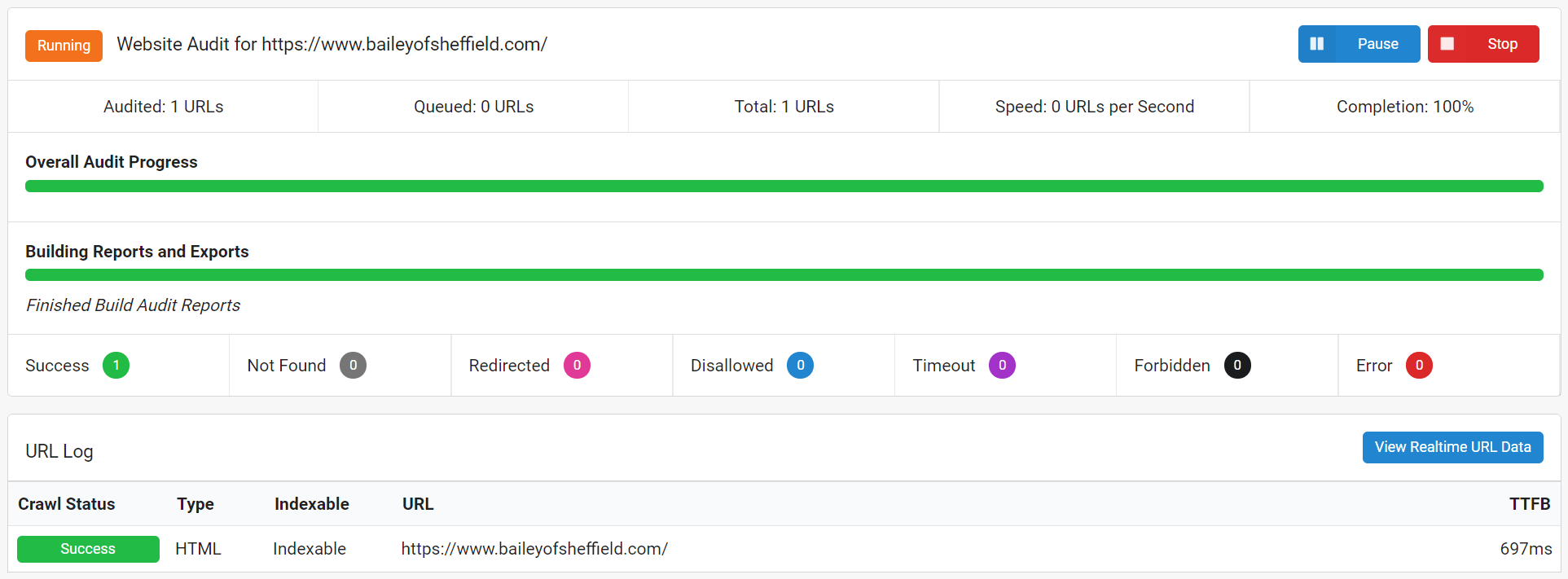
Адна старонка.
Калі Google прыйшоў у іх першую хвалю індэксацыі, усе яны знайшлі б гэта адна старонкі. І адна старонка з вельмі мала на ім, пры гэтым.
Таму сайты, як гэтага трэба звяртацца па-рознаму. Замест таго, каб проста загрузіць і разбору HTML-файл, абходчык па сутнасці трэба стварыць старонку, як браўзэр будзе рабіць для звычайнага карыстальніка, дазваляючы ўсё змесціва атрымаць аказваецца, выпусціўшы ўсе JavaScript, каб прывесці ў дынамічнае змесціва.
Па сутнасці, сканер павінен прыкінуцца браўзэр, хай усё нагрузкі кантэнту, і толькі потым пайсці і атрымаць HTML для разбору.
Вось чаму вам патрэбен сучасны шукальнік, такія як Sitebulb, усталяваны ў рэжыме Chrome гусенічнага, поўзаць сайты, як гэта.
Як Crawl JavaScript вэб-сайтаў з Sitebulb
Кожны раз, калі вы стварылі новы праект у Sitebulb, вам неабходна выбраць параметры аналізу, такія як праверка на AMP або вылічэнне ацэнкі хуткасці старонкі.
Ўстаноўка абходчык па змаўчанні з'яўляецца HTML гусенічнай, так што вы павінны выкарыстоўваць выпадальнае меню для выбару Chrome Crawler. У некаторых выпадках, Sitebulb выявіць, што сайт выкарыстоўвае JavaScript рамкі, і папярэдзіць вас выкарыстоўваць Chrome Crawler (і ён будзе папярэдне выбраць яго для вас, падобныя на малюнак унізе).
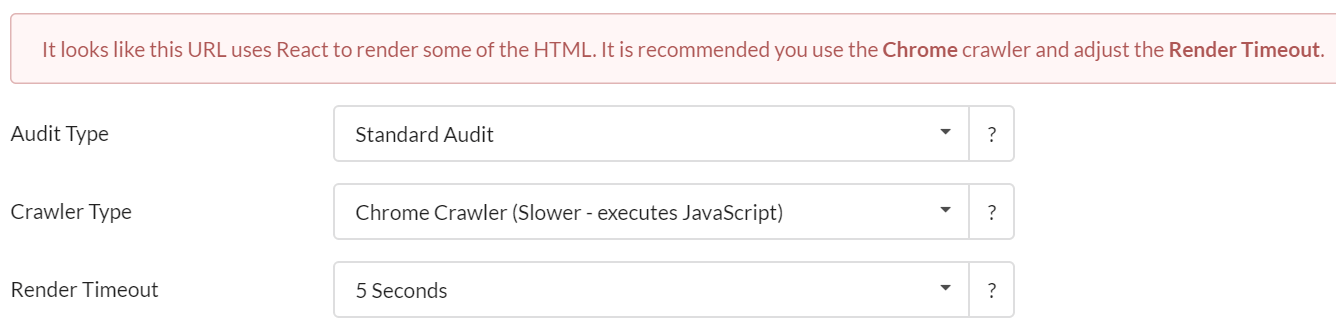
У гэтых выпадках новая опцыя налады з'яўляецца, «рэндэру Тайм-аўт».
Большасць людзей, верагодна, не будзе ведаць, што рэндэру Timeout ставіцца ці як усталяваць яго. Калі вы не хочаце ведаць, прапусціць раздзел ніжэй, і проста пакінуць яго ў рэкамендаваных 5 секунд. У адваротным выпадку, чытайце далей.
Што гэта рэндэру Тайм-аўт?
Візуалізацыі тайм-аўт, па сутнасці, як доўга Sitebulb будзе чакаць рэндэрынгу, каб завяршыць, перш чым прымаць «HTML» здымак кожнай вэб-старонкі.
Джасцін Брыгс апублікаваў пост, які з'яўляецца выдатным дапаможнікам для пачаткоўцаў па праца з змесцівам JavaScript для SEO , Якая дапаможа нам растлумачыць, дзе рэндэру таймаўту змяшчаецца ў.
Я настойліва раю вам пайсці і прачытаць увесь пост, але па меншай меры, ніжэй скрыншот паказвае паслядоўнасць падзей, якія адбываюцца, калі браўзэр запытвае старонку, якая залежыць ад JavaScript аказанага зместу:

«Рэндэру Тайм-аўт» перыяд, які выкарыстоўваецца Sitebulb пачынаецца толькі пасля таго, як # 1, на першапачатковы запыт. Такім чынам, па сутнасці, рэндэру таймаўт гэтага часу вы павінны чакаць усё, каб загрузіць і зрабіць на гэтай старонцы. Скажам, у вас ёсць рэндэру Тайм-аўт усталяваны на 4 секунды, гэта азначае, што кожная старонка мае 4 секунды для ўсяго кантэнту, каб скончыць загрузку і любыя канчатковыя змены ўступілі ў сілу.
Усё, што змяняецца пасля гэтых 4-х секунд не будуць захопленыя і запісаны Sitebulb.
Прыклад візуалізацыі тайм-аўту
Я пакажу на прыкладзе, нашы сябры зноў Бейлі Шэфілда , Калі я скануюць сайт, без рэндэрынгу тайм-аўт на ўсіх, я атрымліваю ў агульнай складанасці 30 URL. Калі я выкарыстоўваю 5-секундны тайм-аўт, я атрымліваю 51 URL, амаль у два разы больш.

(Рэвізійная з 1 URL шукальнікам, калі вы памятаеце, быў ад поўзання з HTML Crawler).
Пакапаўшыся ў трохі больш падрабязна аб гэтых двух Chrome поўзае, былі больш за 14 ўнутраных HTML URL, знойдзеных з 5 секунднай затрымкай. Гэта азначае, што ў аўдыце з не аказвае тайм-аўт, змест, якое змяшчае спасылкі на гэтыя URL-адрас не былі загружаныя, калі Sitebulb ўзяў здымак.
Відавочна, што гэта можа аказаць глыбокае ўздзеянне на ваша разуменне вэб-сайта і яго архітэктуры, якія могуць быць вылучаныя шляхам параўнання двух карт абыходу:
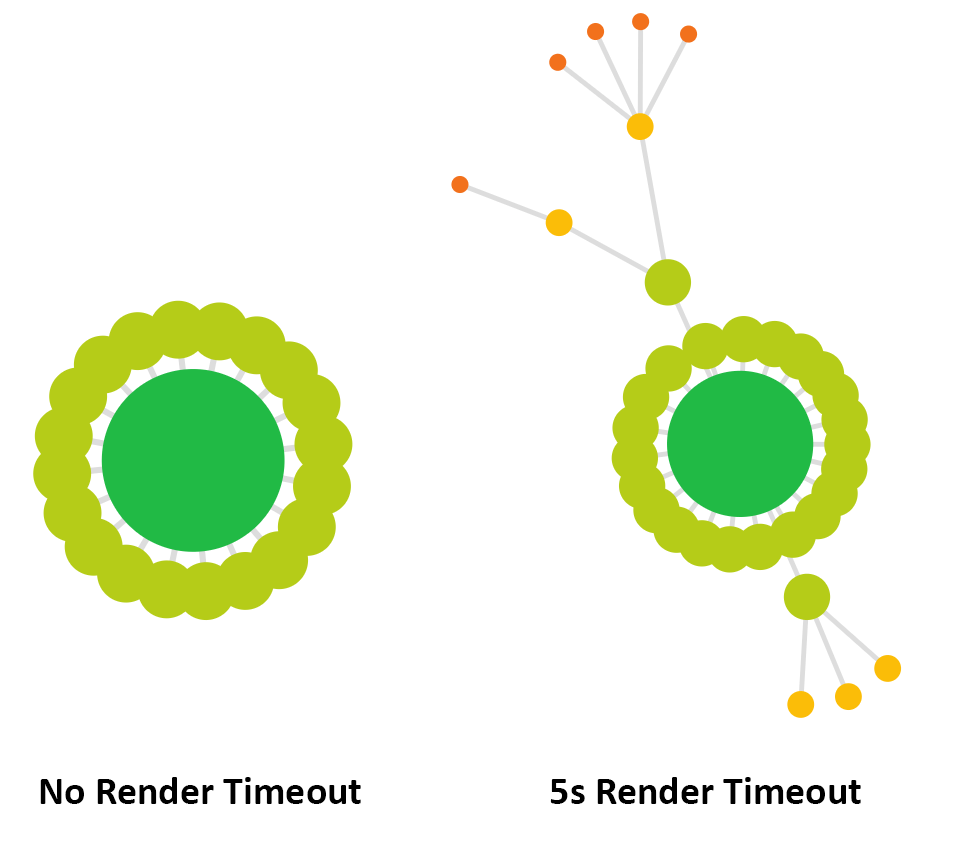
У дадзеным выпадку, гэта было вельмі важна, каб усталяваць рэндэру Тайм-аўт для таго, каб Sitebulb, каб убачыць усё змесціва.
Рэкамендуецца рэндэру Тайм-аўт
Разуменне таго, чаму існуе рэндэру Тайм-аўт на самай справе не дапаможа нам вырашыць, што ўсталяваць яго на. Мы гойсалі ў Інтэрнэце для пацверджання ад Google пра тое, як доўга яны чакаюць кантэнту для загрузкі, але мы не знайшлі яго ў любым месцы.
Тое, што мы знайшлі, аднак, што большасць людзей, здаецца, сыходзяцца ў меркаванні, што 5 секунд, як правіла, лічыцца "аб праве. Пакуль мы не бачым нічога канкрэтнага ад Google, або ёсць шанец выканаць яшчэ некалькі тэстаў нашых уласных, мы будзем рэкамендаваць 5 секунд для рэндэру тайм-аўт.
Але ўсё гэта пакажа вам , з'яўляецца набліжаным , што Google можа бачыць. Калі вы хочаце , каб сканаваць ўсё змесціва на вашым сайце, то вам неабходна развіваць больш глыбокае разуменне таго , як змест на вашым сайце на самай справе робіць.
Каб зрабіць гэта, мы вернемся да Devtools кансолі Chrome. Пстрыкніце правай кнопкай мышы на старонцы і націсніце «Праверыць», затым выберыце «Сетка» з укладак ў кансолі, а затым перазагрузіце старонку. Я разьмясьціў док справа ад майго экрана, каб прадэманстраваць:

Трымаеце вочы на вадаспад графіцы, які будуе, і таймінгі, якія запісаны ў зводных панэлях у ніжняй часткі:
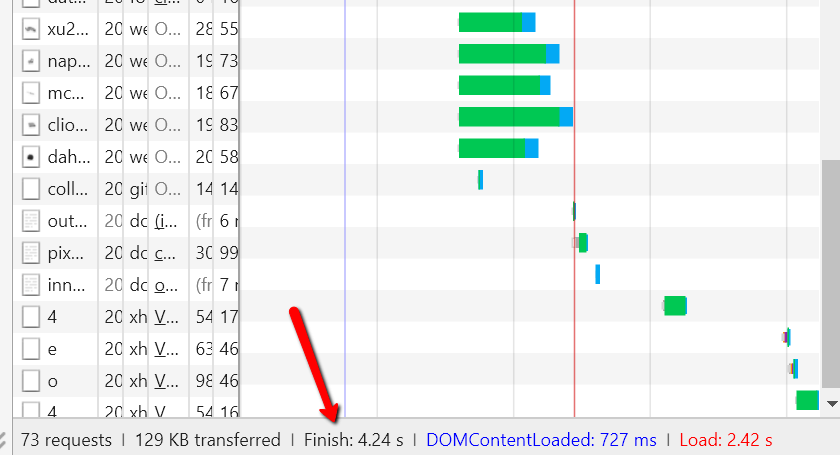
Такім чынам, мы маем 3 разы запісана тут:
- DOMContentLoaded: 727 мс (= 0,727 с)
- Нагрузка: 2,42 s
- Аздабленне: 4.24 s
Вы можаце знайсці вызначэння для «DOMContentLoaded» і «Load» з малюнка вышэй, што я ўзяў з пасады Джасцін Брыгс. Час «Finish» дакладна, што, калі змест цалкам аказаны, і любыя змены або асінхронныя сцэнары завяршэння.
Калі ўтрыманне вэб-сайта залежыць ад змен JavaScript, то вам сапраўды трэба чакаць часу «Гатова», так што выкарыстоўвайце гэта як правіла для вызначэння рэндэрынгу тайм-аўт.
Майце на ўвазе, што да гэтага часу мы толькі глядзелі на адной старонцы. Для таго, каб распрацаваць больш дакладную карціну таго, што адбываецца, вы павінны праверыць колькасць старонак шаблонаў / старонак і праверыць таймінгі для кожнага з іх.
Калі вы збіраецеся поўзаць з Chrome Crawler, мы настойліва раім вам паэксперыментаваць з рэндэрынгу тайм-аўт, каб вы маглі ўсталяваць свае праекты да правільна сканаваць ўсе матэрыялы кожны раз.
Пабочныя эфекты поўзаць з JavaScript
Амаль кожны вэб-сайт вы будзеце калі-небудзь бачыць выкарыстоўвае JavaScript у нейкай ступені - інтэрактыўныя элементы, усплывальныя вокны, аналітычныя коды, дынамічныя элементы старонкі ... усё кантралюецца JavaScript.
Тым не менш, большасць сайтаў не выкарыстоўваюць JavaScript, каб дынамічна змяняць большасць кантэнту на дадзенай вэб-старонцы. Для вэб-сайтаў, як гэта, існуе ніякай рэальнай карысці ў кішыць JavaScript не ўключаны. На самай справе, з пункту гледжання справаздачнасці, няма літаральна ніякай розніцы:

І ёсць на самой справе пара мінусаў паўзуць з Chrome Crawler, напрыклад:
- Сканіраванне з Chrome Crawler азначае, што вы павінны атрымліваць і візуалізаваць кожную старонку рэсурсу (JavaScript, малюнка, CSS і г.д ...) - што больш рэсурсаёмістых як для вашай лакальнай машыне, якая працуе Sitebulb, і сервер, што сайт з'яўляецца размешчаны на.
- Як прамы вынік # 1 вышэй, поўзаць з Chrome Crawler адбываецца павольней, чым з HTML Crawler, асабліва калі вы ўсталявалі доўгі рэндэру тайм-аўту. На некаторых сайтах, а таксама з некаторымі наладамі, ён можа ў канчатковым выніку прымае 6-10 X даўжэй.
Такім чынам, калі вам не трэба поўзаць з Chrome Crawler , паколькі сайт выкарыстоўвае JavaScript рамкі, ці таму , што вы канкрэтна хочаце паглядзець , як сайт рэагуе на гусенічным JavaScript, то мае сэнс сканаваць з HTML Crawler па змаўчанні.
Як выявіць JavaScript сайты
Я выкарыстаў фразу «JavaScript» Сайты для сцісласці, дзе тое, што я на самой справе маю на ўвазе "вэб-сайтах, якія залежаць ад JavaScript-які адлюстроўваецца змесціва.
Найбольш верагодна, што тып вэб-сайтаў, вы сутыкнецеся будзе выкарыстоўваць адзін з якія павялічваюцца папулярных фреймворков, такіх як:
- вуглаваты
- рэагаваць
- ўбудоўваць
- пазваночнік
- Ую
- метэор
Калі вы маеце справу з вэб-сайта пад кіраваннем адной з гэтых структур, важна, што вы разумееце, як мага хутчэй, што вы маеце справу з вэб-сайтам, які ў корані адрозніваецца ад вэб-сайта без JavaScript.
кліент Briefing
Відавочна, што першы порт заходу, вы можаце зэканоміць час, робячы адкрыццё працу з дбайным інструктажом з кліентам або іх камандамі распрацоўшчыкаў.
Тым не менш, у той час як гэта прыемна думаць, што кожны кліент брыфінг дасць вам такую інфармацыі фронт, я ведаю з горкага вопыту, што яны не заўсёды маюць быць, здавалася б, відавочнымі дэталямі ...
спроба кролем
Ўзворванне галаву першым у аўдыце з Chrome Crawler на самай справе не будзе каштаваць вам занадта шмат часу, так як нават большасць вэб-сайтаў «нішы» маюць больш чым адзін URL.
Хоць гэта не азначае , што вы вызначана маем справу з сайтам JavaScript, гэта будзе вельмі добры паказчык.
Гэта, безумоўна, варта мець на ўвазе, аднак, у выпадку, калі вы тыпу сэт-он-і-забыўся-то, ці вы, як правіла, пакідаюць на ноч Sitebulb з чаргой сайтаў з аўдытам ... да раніцы вы будзеце горкае расчараванне.
Кіраўніцтва па правядзенні інспекцыі
Вы можаце таксама выкарыстоўваць інструменты Google, каб дапамагчы вам зразумець, як вэб-сайт, разам узятыя. З дапамогай Google Chrome, пстрыкніце правай кнопкай мышы ў любым месцы на вэб-старонцы і выберыце «Праверыць», каб адкрыць DevTools кансолі ў Chrome ,
Затым націсніце F1, каб адкрыць налады. Пракруціць ўніз, каб знайсці адладчык, і адзначце "Адключыць JavaScript.
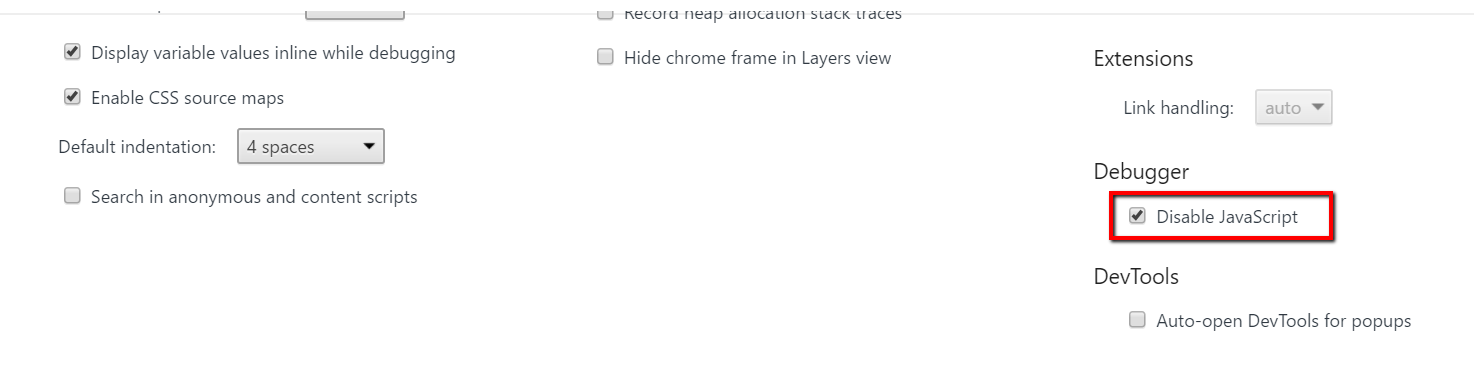
Затым пакіньце Devtools кансоль адкрытай і абновіце старонку. Ці застаецца ўтрыманне сапраўды гэтак жа, ці ж гэта ўсё знікне?
Гэта тое, што адбываецца ў маёй Bailey прыкладу Шэфілд:
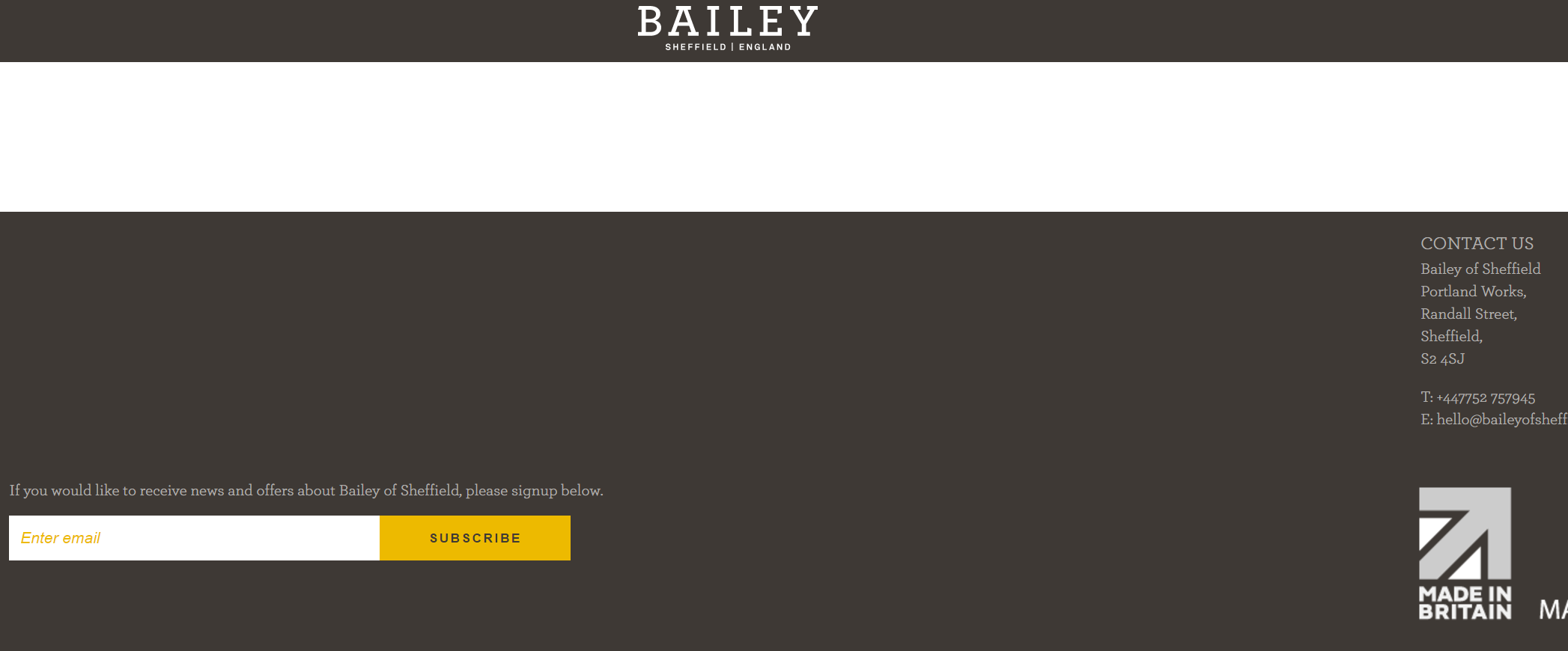
Звярніце ўвагу, што-то не хапае?
Нягледзячы на тое, што гэта даволі відавочны прыклад вэб-сайт не працуе з JavaScript адключаны, ён таксама стаіць мець на ўвазе, што некаторыя сайты загружаюцца толькі частку змесціва з выкарыстаннем JavaScript (напрыклад, галерэю малюнкаў), таму часта варта праверка колькасць шаблонаў старонак, як гэта.
далейшае чытанне
JavaScript SEO з'яўляецца адносна новым і без дакументаў, аднак мы сабралі спіс усё лепшыя рэсурсы для вывучэння JavaScript SEO , У тым ліку правадыроў, эксперыментаў і відэа. Мы будзем трымаць пост рэсурсу ў курсе новых публікацый і распрацовак.
Што гэта рэндэру Тайм-аўт?Ці застаецца ўтрыманне сапраўды гэтак жа, ці ж гэта ўсё знікне?


