
- Próbuję zaindeksować witrynę JavaScript bez renderowania
- Jak indeksować strony internetowe JavaScript za pomocą Sitebulb
- Co to jest limit czasu renderowania?
- Przykład limitu czasu renderowania
- Zalecany limit czasu renderowania
- Skutki uboczne indeksowania za pomocą JavaScript
- Jak wykryć strony JavaScript
- Odprawa klienta
- Próbuję przeszukać
- Kontrola ręczna
- Dalsze czytanie
Наша команда-партнер Artmisto
Indeksowanie stron internetowych w 2018 r. Nie jest tak proste, jak miało to miejsce kilka lat temu, a to głównie ze względu na wzrost wykorzystania struktur JavaScript, takich jak Angular, React i Meteor.
Tradycyjnie robot przeszukiwałby dane, pobierając dane ze statycznego kodu HTML, a do niedawna większość stron, które można spotkać, mogłaby zostać zaindeksowana w ten sposób.
Jeśli jednak spróbujesz przeszukać witrynę zbudowaną w ten sposób w Angular, nie zajdziesz zbyt daleko (dosłownie). Aby „zobaczyć” kod HTML strony internetowej (oraz treść i linki w niej zawarte), robot musi przetworzyć cały kod na stronie i faktycznie renderować zawartość.
Google obsługuje to w podejściu dwufazowym . Początkowo indeksują i indeksują w oparciu o statyczny HTML („pierwsza fala” indeksowania). Następnie, gdy będą mieli zasoby dostępne do renderowania strony, wykonują drugą falę indeksowania na podstawie renderowanego HTML.
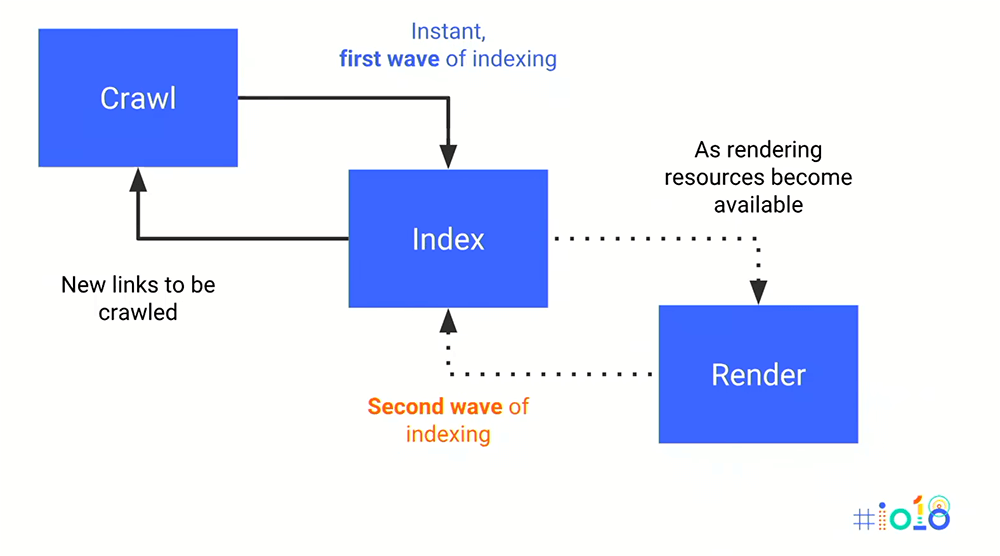
Próbuję zaindeksować witrynę JavaScript bez renderowania
Najpierw zbadamy, jak wyglądałaby ta pierwsza fala indeksowania witryny zbudowanej w środowisku JavaScript.
Mój przyjaciel prowadzi stronę internetową zbudowaną w kręgosłupie i jego strona internetowa stanowi świetny przykład, aby zobaczyć, co się dzieje.
Rozważać strona produktu dla ich najpopularniejszego produktu. W Chrome -> Sprawdź, widzimy h1 na stronie:
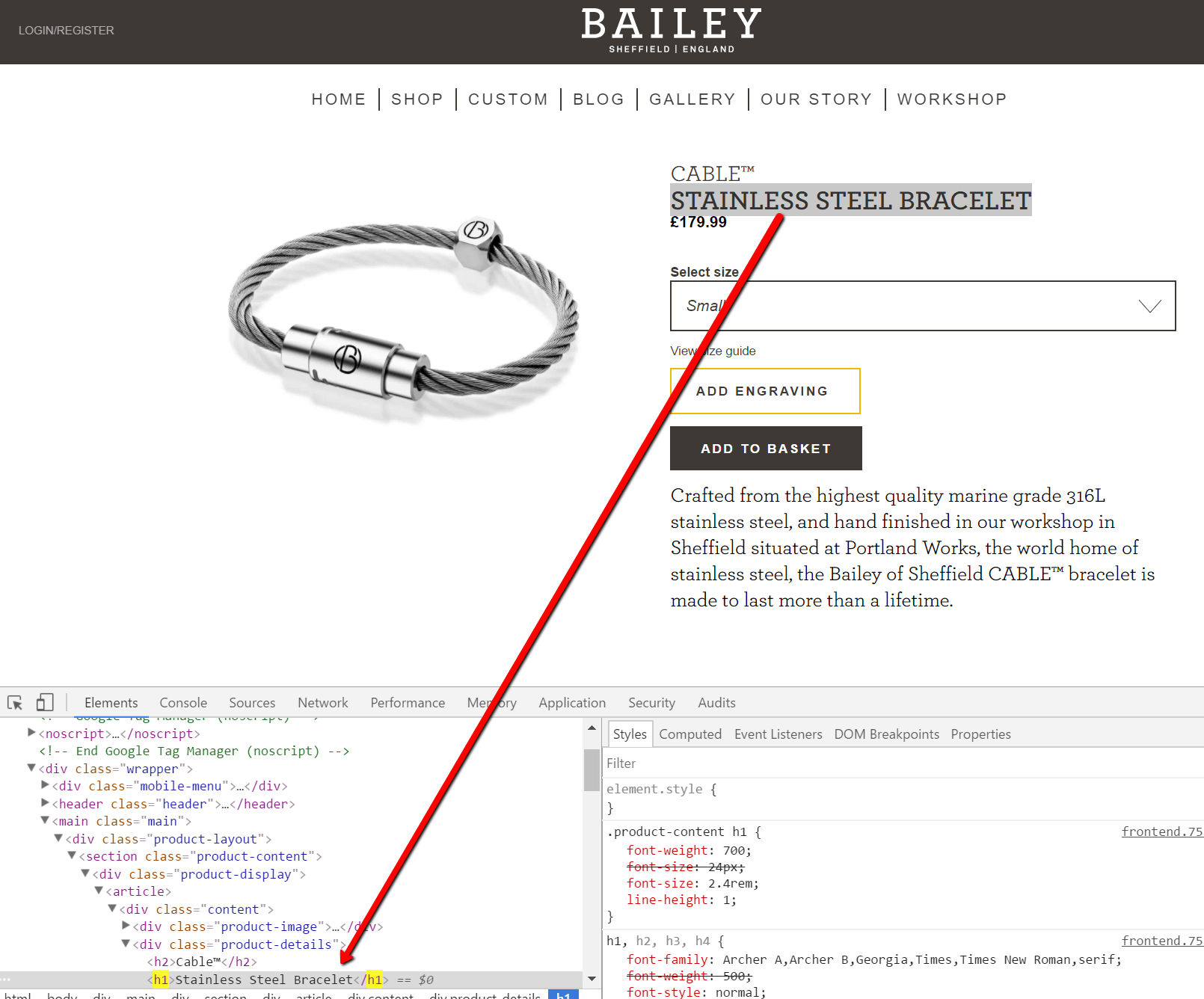
Jeśli jednak na tej stronie wyświetlimy tylko źródło, nie ma h1 w zasięgu wzroku:
Przewijanie dalej w dół strony widoku źródła pokaże ci tylko kilka skryptów i jakiś tekst zastępczy. Po prostu nie widać mięsa i kości strony - obrazów produktu, opisu, specyfikacji technicznej, wideo, a co najważniejsze, linków do innych stron.
Jeśli więc próbowałeś zaindeksować tę stronę w tradycyjny sposób (za pomocą „robota HTML”), wszystkie dane, które przeszukiwacz zazwyczaj wyodrębniałby, są w zasadzie dla niego niewidoczne. I to właśnie otrzymasz:
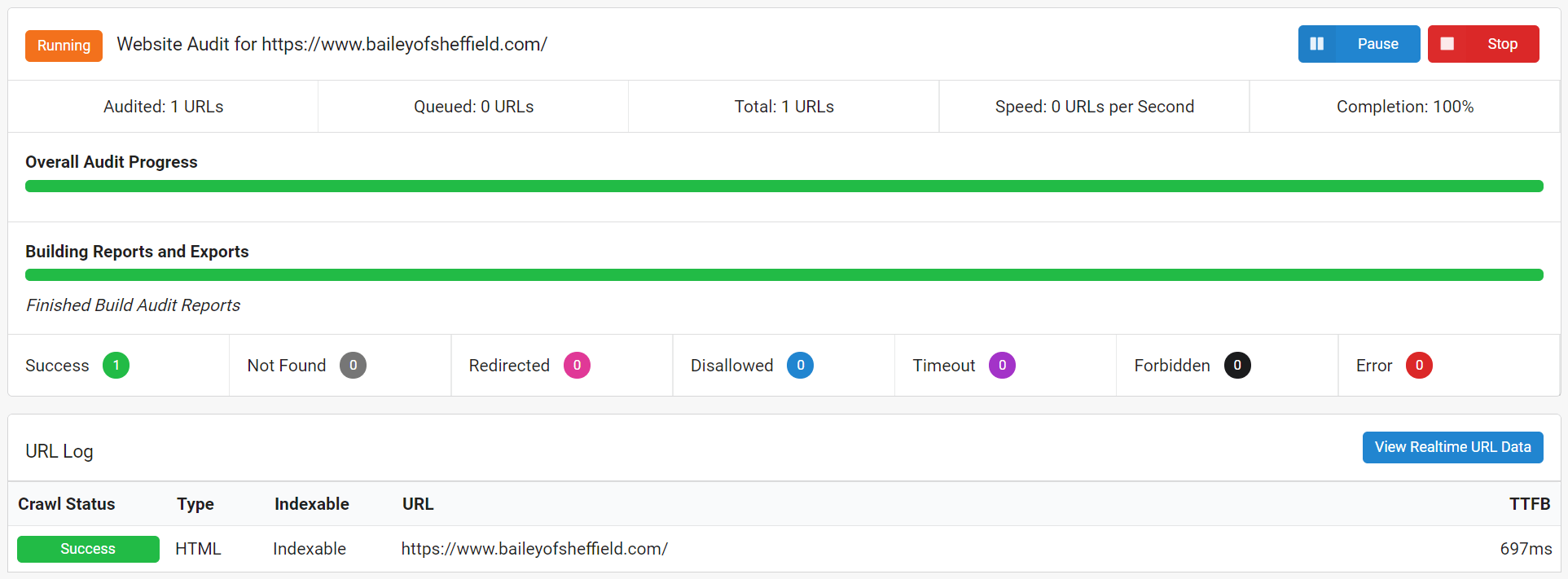
Jedna strona.
Gdyby Google przyszedł na pierwszą falę indeksowania, wszystko, co mogliby znaleźć, to ta jedna strona. I na tej stronie jedna strona z bardzo małą ilością.
Więc takie strony internetowe muszą być traktowane inaczej. Zamiast po prostu pobierać i analizować plik HTML, przeszukiwacz zasadniczo musi zbudować stronę, tak jak zrobi to przeglądarka dla zwykłego użytkownika, pozwalając na renderowanie całej zawartości, uruchamiając cały JavaScript, aby wprowadzić dynamiczną treść.
W istocie robot musi udawać, że jest przeglądarką, załadować całą zawartość, a dopiero potem przejść i przetworzyć kod HTML.
Właśnie dlatego potrzebny jest nowoczesny robot indeksujący, taki jak Sitebulb, ustawiony w trybie przeszukiwacza Chrome, aby indeksować takie witryny.
Jak indeksować strony internetowe JavaScript za pomocą Sitebulb
Za każdym razem, gdy tworzysz nowy projekt w Bulbie witryny, musisz wybrać ustawienia analizy, takie jak sprawdzanie AMP lub obliczanie wyników szybkości strony.
Domyślnym ustawieniem przeszukiwacza jest robot indeksujący HTML, dlatego należy użyć listy rozwijanej, aby wybrać robot indeksujący Chrome. W niektórych przypadkach usługa Sitebulb wykryje, że witryna korzysta ze struktury JavaScript, i ostrzeże Cię, aby skorzystać z robota indeksującego Chrome (i wcześniej go wybierze, tak jak na poniższym obrazku).
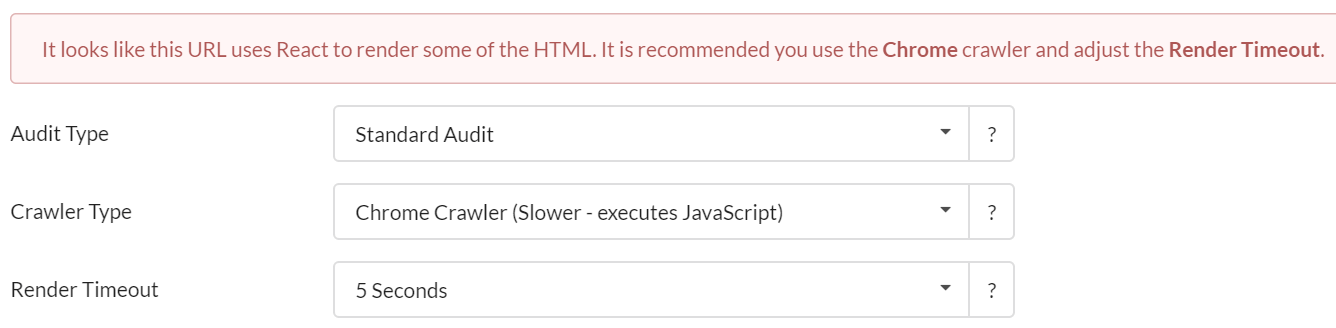
W takich przypadkach pojawi się nowa opcja ustawień „Limit czasu renderowania”.
Większość ludzi prawdopodobnie nie wie, do czego odnosi się limit czasu renderowania lub jak go ustawić. Jeśli wolisz nie wiedzieć, pomiń sekcję poniżej i pozostaw ją w zalecanych 5 sekundach. W przeciwnym razie czytaj dalej.
Co to jest limit czasu renderowania?
Limit czasu renderowania jest zasadniczo taki, jak długo witrynabulb będzie czekać na zakończenie renderowania przed wykonaniem „migawki HTML” każdej strony internetowej.
Justin Briggs opublikował post, który jest doskonałym podkładem obsługa treści JavaScript dla SEO , które pomogą nam wyjaśnić, gdzie mieści się limit czasu renderowania.
Zdecydowanie radzę przeczytać i przeczytać cały post, ale przynajmniej poniższy zrzut ekranu pokazuje sekwencję zdarzeń, które pojawiają się, gdy przeglądarka żąda strony zależnej od treści renderowanych przez JavaScript:

Okres „Renderowanie limitu czasu” używany przez funkcję Sitebulb rozpoczyna się tuż po # 1, początkowym żądaniu. Zasadniczo limit czasu renderowania to czas, w którym należy poczekać, aż wszystko zostanie załadowane i renderowane na stronie. Załóżmy, że ustawiono Limit czasu renderowania na 4 sekundy, co oznacza, że każda strona ma 4 sekundy na dokończenie ładowania całej zawartości i na ostateczne zmiany, które zostaną wprowadzone.
Wszystko, co zmieni się po tych 4 sekundach, nie zostanie przechwycone i zarejestrowane przez Sitebulb.
Przykład limitu czasu renderowania
Pokażę na przykładzie naszych przyjaciół ponownie w Bailey z Sheffield . Jeśli zaindeksuję witrynę bez limitu czasu renderowania, otrzymam w sumie 30 adresów URL. Jeśli użyję limitu czasu 5 sekund, otrzymam 51 adresów URL, prawie dwa razy więcej.

(Jeśli pamiętasz, inspekcja z 1 przeszukiwanym adresem URL pochodziła z przeszukiwania za pomocą robota indeksującego HTML).
Wpisując trochę więcej szczegółów na temat tych dwóch indeksowań Chrome, znaleziono 14 dodatkowych wewnętrznych adresów URL HTML z 5 sekundowym limitem czasu. Oznacza to, że w Audycie bez limitu czasu renderowania zawartość, która zawiera odsyłacze do tych adresów URL, nie została załadowana, gdy witryna Sitebulb wykonała migawkę.
Oczywiście może to mieć głęboki wpływ na zrozumienie witryny i jej architektury, które można podkreślić, porównując dwie mapy indeksujące:
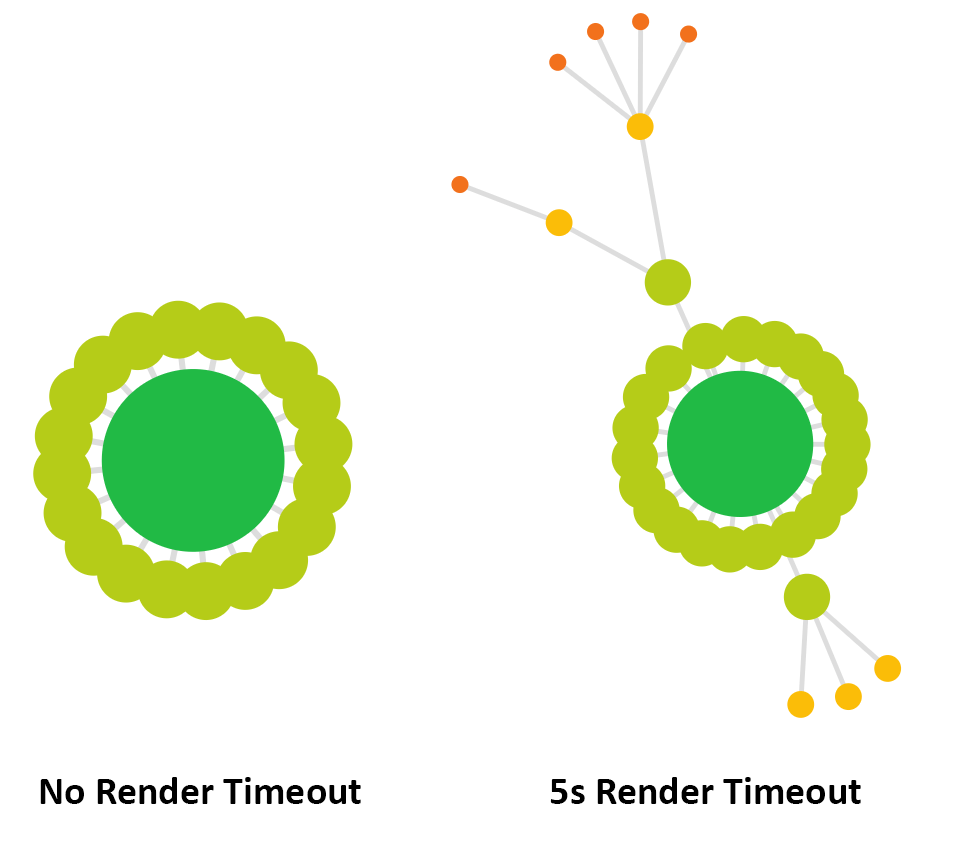
W tym przypadku bardzo ważne było ustawienie limitu czasu renderowania, aby funkcja Sitebulb mogła zobaczyć całą zawartość.
Zalecany limit czasu renderowania
Zrozumienie, dlaczego istnieje Czas oczekiwania na renderowanie, nie pomaga nam w podjęciu decyzji, na co go ustawić. Przeszukaliśmy internet w celu potwierdzenia przez Google, jak długo czekają na załadowanie treści, ale nie znaleźliśmy go nigdzie.
Odkryliśmy jednak, że większość ludzi zgadza się, że 5 sekund jest ogólnie uważane za „w porządku”. Dopóki nie zobaczymy niczego konkretnego z Google lub nie będziemy mieli szansy na wykonanie własnych testów, zalecamy 5 sekund na limit czasu renderowania.
Ale wszystko to pokaże, że jest to przybliżenie tego, co Google może zobaczyć . Jeśli chcesz indeksować WSZYSTKIE treści w swojej witrynie, musisz lepiej zrozumieć, w jaki sposób treści na Twojej stronie faktycznie się wyświetlają.
Aby to zrobić, wrócimy do konsoli DevTools Chrome. Kliknij prawym przyciskiem myszy stronę i naciśnij „Sprawdź”, a następnie wybierz „Sieć” z kart w konsoli, a następnie ponownie załaduj stronę. Ustawiłem stację z prawej strony ekranu, aby pokazać:

Miej oko na wykres wodospadu, który się buduje, i czasy, które są zapisane na pasku podsumowania na dole:
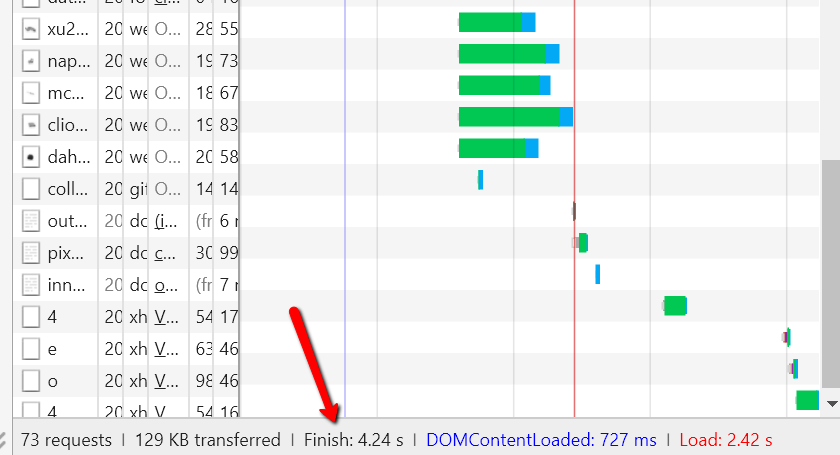
Mamy więc 3 razy zapisane tutaj:
- DOMContentLoaded: 727 ms (= 0,727 s)
- Obciążenie: 2,42 s
- Wykończenie: 4,24 s
Definicje „DOMContentLoaded” i „Load” można znaleźć na obrazku powyżej, który zrobiłem z posta Justina Briggsa. Czas zakończenia jest dokładnie taki, kiedy treść jest w pełni renderowana, a wszelkie zmiany lub skrypty asynchroniczne zostały zakończone.
Jeśli zawartość strony zależy od zmian w JavaScript, to naprawdę musisz poczekać na czas „Zakończ”, więc użyj tego jako reguły do określania limitu czasu renderowania.
Pamiętaj, że do tej pory patrzyliśmy tylko na jedną stronę. Aby uzyskać lepszy obraz tego, co się dzieje, musisz sprawdzić liczbę stron / szablonów stron i sprawdzić czasy dla każdego z nich.
Jeśli zamierzasz indeksować za pomocą robota indeksującego Chrome, zachęcamy Cię do dalszego eksperymentowania z limitem czasu renderowania, aby ustawić projekty tak, aby za każdym razem poprawnie indeksował całą zawartość.
Skutki uboczne indeksowania za pomocą JavaScript
Prawie każda strona, którą kiedykolwiek zobaczysz, wykorzystuje do pewnego stopnia JavaScript - elementy interaktywne, wyskakujące okienka, kody analityczne, dynamiczne elementy strony ... wszystko kontrolowane przez JavaScript.
Jednak większość stron internetowych nie wykorzystuje JavaScript do dynamicznej zmiany większości treści na danej stronie internetowej. W przypadku stron takich jak ta, indeksowanie z włączoną obsługą JavaScript nie przynosi żadnych rzeczywistych korzyści. W rzeczywistości, jeśli chodzi o raportowanie, nie ma dosłownie żadnej różnicy:

W indeksowaniu Chrome Crawlerów jest kilka wad, na przykład:
- Indeksowanie za pomocą robota indeksującego Chrome oznacza, że musisz pobierać i renderować każdy zasób strony (JavaScript, obrazy, CSS itp.) - który jest bardziej intensywny dla zasobów zarówno na komputerze lokalnym, na którym działa Sitebulb, jak i na serwerze, na którym znajduje się witryna hostowane na.
- Bezpośrednim wynikiem powyższego # 1 jest indeksowanie za pomocą robota indeksującego Chrome wolniej niż w przypadku robota indeksującego HTML, zwłaszcza jeśli ustawiono długi limit czasu renderowania. W niektórych witrynach i przy niektórych ustawieniach ukończenie ich może potrwać 6-10 X.
Jeśli więc nie musisz indeksować za pomocą robota indeksującego Chrome, ponieważ witryna korzysta ze struktury JavaScript, lub dlatego, że chcesz zobaczyć, jak witryna odpowiada na przeszukiwacz JavaScript, warto zaindeksować domyślnie za pomocą robota indeksującego HTML .
Jak wykryć strony JavaScript
Użyłem wyrażenia „strony internetowe JavaScript” w celu zwięzłości, gdzie w rzeczywistości mam na myśli „strony internetowe, które zależą od treści renderowanych w języku JavaScript”.
Najprawdopodobniej typ stron internetowych, z którymi się spotykasz, będzie wykorzystywał jedną z coraz popularniejszych platform JavaScript, takich jak:
- Kątowy
- Reagować
- Osadzać
- Kręgosłup
- Vue
- Meteor
Jeśli masz do czynienia ze stroną internetową, na której działa jeden z tych frameworków, ważne jest, abyś zrozumiał jak najszybciej, że masz do czynienia z witryną, która zasadniczo różni się od strony bez JavaScript.
Odprawa klienta
Oczywiście pierwszy port zawinięcia, możesz zaoszczędzić czas wykonując prace odkrywcze dzięki szczegółowej informacji od klienta lub jego zespołu.
Jednakże, choć miło jest myśleć, że każda odprawa od klienta da ci tego rodzaju informacje z góry, wiem z bolesnego doświadczenia, że nie zawsze pojawiają się z pozornie oczywistymi szczegółami ...
Próbuję przeszukać
Pierwsze zajęcie głowy w audycie za pomocą robota indeksującego Chrome w rzeczywistości nie kosztuje zbyt wiele czasu, ponieważ nawet najbardziej „niszowe” witryny internetowe mają więcej niż jeden adres URL.
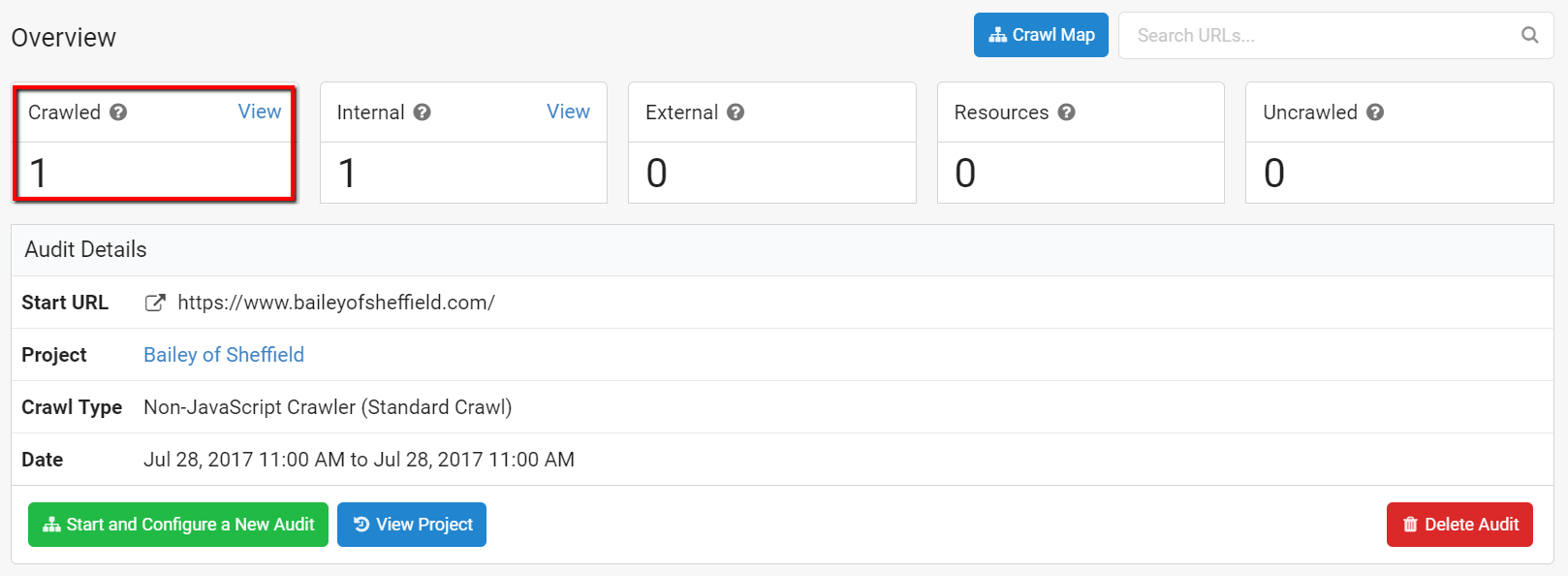
Choć nie oznacza to, że masz do czynienia ze stroną JavaScript, byłby to całkiem dobry wskaźnik.
Na pewno warto jednak pamiętać, na wypadek gdybyś był typem „ustaw i zapomnij” lub masz tendencję do zostawiania dodatku Sitebulb z dnia na dzień z kolejką witryn do audytu… do rana będziesz gorzko rozczarowany.
Kontrola ręczna
Możesz również skorzystać z narzędzi Google, aby pomóc Ci zrozumieć, w jaki sposób strona jest połączona. Korzystając z Google Chrome, kliknij prawym przyciskiem myszy w dowolnym miejscu na stronie internetowej i wybierz „Sprawdź”, aby ją wyświetlić Konsola DevTools Chrome .
Następnie naciśnij F1, aby wyświetlić ustawienia. Przewiń w dół, aby znaleźć debuger, i zaznacz „Wyłącz JavaScript”.
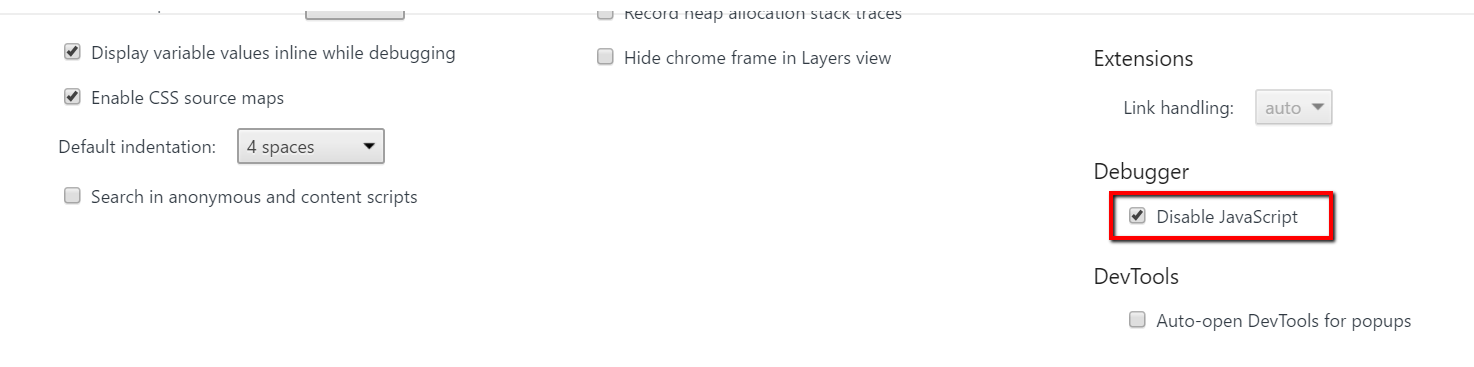
Następnie otwórz konsolę DevTools i odśwież stronę. Czy zawartość pozostaje taka sama, czy też wszystko znika?
Tak się dzieje w moim przykładzie Bailey of Sheffield:
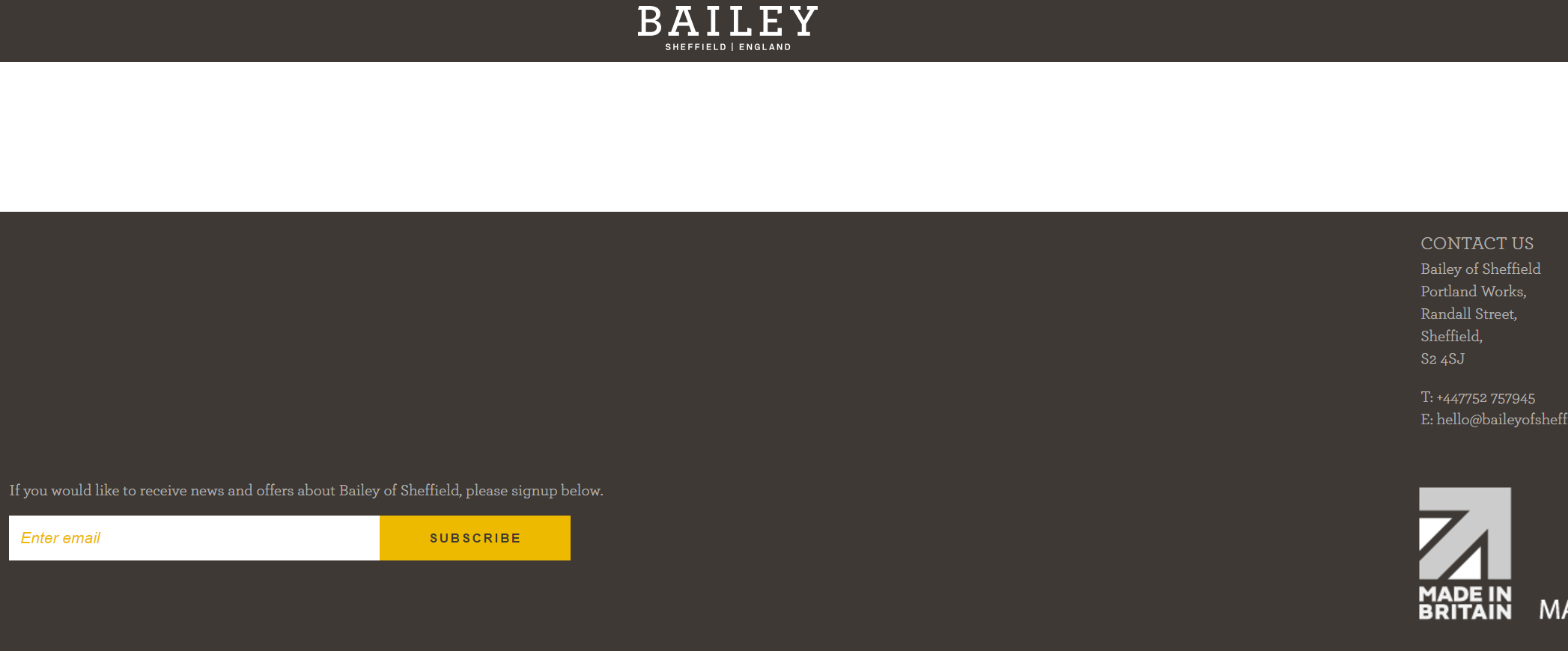
Zauważ, że czegoś brakuje?
Chociaż jest to dość oczywisty przykład strony internetowej, która nie działa z wyłączoną obsługą JavaScript, warto pamiętać, że niektóre witryny ładują tylko część treści w JavaScript (np. Galeria zdjęć), dlatego często warto sprawdzić liczba szablonów stron takich jak ten.
Dalsze czytanie
SEO JavaScript jest wciąż stosunkowo nowy i nieudokumentowany, jednak zestawiliśmy listę wszystkich najlepsze zasoby do nauki SEO JavaScript , w tym przewodniki, eksperymenty i filmy. Będziemy informować na bieżąco o nowych publikacjach i wydarzeniach.
Co to jest limit czasu renderowania?Czy zawartość pozostaje taka sama, czy też wszystko znika?


