
Наша команда-партнер Artmisto
Definicje Przypuśćmy, że chcesz rozwiązać problem (2): f (x) -> min, x О Rn (2) W przestrzeni dwuwymiarowej R2 rozwiązaniu takiego problemu można dać geometryczną ilustrację. Niech punkt x = (x1, x2) leży na płaszczyźnie Ox1x2. Wprowadzamy trzecią współrzędną x3, aby oś współrzędnych Ox3 była prostopadła do płaszczyzny Ox1x2 (rys. 1). Równanie x3 = f (x1, x2) odpowiada powierzchni w przestrzeni trójwymiarowej.
Jeśli funkcja f (x) osiągnie lokalne minimum w punkcie x * О R2, to powierzchnia w pewnym sąsiedztwie punktu x * ma kształt misy (rys. 1).
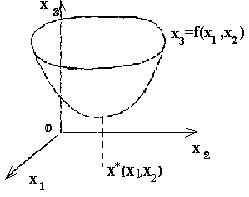
Rys.1
Przypomnijmy, że linie poziomu funkcji f (x1, x2) wywołują rodzinę linii płaszczyzny R2, na której funkcja przyjmuje stałą wartość. Niejawne równanie linii poziomu jest równaniem f (x1, x2) = C. Jeśli funkcja f (x) w R2 ma pojedynczy lokalny punkt minimalny
x * (x * 1, x * 2), wtedy taka funkcja nazywana jest monomodalna. Wzajemne rozmieszczenie jego linii poziomych wygląda jak na Rys.2.
Nazywane są funkcje multimodalne, które mają więcej niż jedno ekstremum. Taka jest na przykład funkcja Himmelblau.
F (x) = (x12 + x2-11) 2+ (x1 + x22-7) 2,
posiadające cztery pojedyncze punkty. Rysunek 3 pokazuje schematycznie linie poziomu tej funkcji.
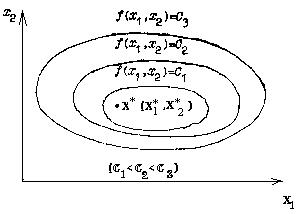
Pic2
Aby znaleźć punkt x * lokalnego minimum funkcji f (x), utwórz sekwencję punktów (przybliżenia do rozwiązania) {x (k)} (k = 0,1, ...) zbieżną do punktu x *
(k = 0,1, ...), zbieżne do punktu x *.
Sekwencja wartości funkcji f (x (k)) powinna być monotonicznie malejąca i ograniczona poniżej:
f (x (0))> = f (x (1))> =. . . > = f (x (k))> =. . . > = f (x (*)).
Geometryczny obraz rozwiązania problemu (2) dla przypadku dwóch zmiennych przypomina zejście do dna miski. Motywuje to nazwy metod rozwiązywania problemu (2) - „metody zejścia”.
Dla różnych metod zniżania najpierw wybierz punkt początkowy sekwencji x (0). Dalsze przybliżenia x (k) są określane przez relacje
x (k + 1) = x (k) + t (k) S (k) (k = 0, 1, 2, ...), (12)
Gdzie S (k) jest kierunkiem wektora zniżania; skalar t (k) i | jest rozwiązaniem problemu minimalizacji jednowymiarowej
f (x (k) + ts (k)) -> min, t R. R. (13)
Zatem zadanie znalezienia minimum funkcji kilku zmiennych jest zredukowane do sekwencji jednowymiarowych problemów minimalizacji (13) w zmiennej t na segmentach n-wymiarowej przestrzeni przechodzącej przez punkty x (k) w kierunku wektorów S (k).
Metody zejścia są rozróżniane przez wybór wektora zniżania i metodę zmniejszania problemu minimalizacji jednowymiarowej.
Rozwiązując sekwencję problemów (12), możemy ograniczyć się do metody skanowania w celu znalezienia minimum funkcji jednej zmiennej. Wybierając dowolnie punkt początkowy x (0) i rozmiar początkowego kroku h ze zmienną t, w metodzie skanowania można uzyskać różne minimalne punkty funkcji multimodalnej.
Jeśli funkcja f (x) jest monomodalna, to niezależnie od wyboru punktu początkowego trajektoria wyszukiwania powinna prowadzić do pojedynczego punktu lokalnego minimum tej funkcji.
Przytłaczająca liczba rzeczywistych problemów optymalizacyjnych o znaczeniu praktycznym jest wielowymiarowa: w nich funkcja celu zależy od kilku argumentów, a czasami ich liczba może być dość duża.
Przypomnijmy na przykład problem produkcji chemicznej. Zauważyliśmy, że funkcja celu w nim zależy od temperatury, a przy pewnym wyborze jego wydajności (wyjście interesującego nas produktu) okazuje się być maksymalne. Jednak wraz z temperaturą wydajność zależy również od ciśnienia, stosunku między stężeniami surowców wejściowych, katalizatorów i wielu innych czynników. Zatem wybór najlepszych warunków produkcji chemicznej jest typowym problemem optymalizacji wielowymiarowej. Matematyczne sformułowanie takich problemów jest podobne do ich sformułowania w przypadku jednowymiarowym: poszukiwana jest najmniejsza (największa) wartość funkcji celu określonej na pewnym zbiorze E możliwych wartości jej argumentów. W przypadku, gdy funkcja jest ciągła, a zbiór E jest zamkniętą domeną ograniczoną, twierdzenie W ten sposób rozróżniamy klasę problemów optymalizacyjnych, dla których zagwarantowane jest istnienie rozwiązania, w przyszłości zawsze zakładamy, nie określając tego, że wszyscy rozważają zadania należą do tej klasy, podobnie jak w przypadku jednowymiarowym, charakter zadania, a co za tym idzie, możliwe metody rozwiązania zależą zasadniczo od informacji o funkcji celu, która jest nam dostępna w procesie jej badań, W niektórych przypadkach funkcja celu jest określona formułą analityczną, która jest funkcją różniczkowalną Następnie można obliczyć jego pochodne cząstkowe, aby uzyskać wyraźne wyrażenie gradientu, które określa funkcję zwiększającą się i zmniejszającą w funkcji definiującej w każdym punkcie,
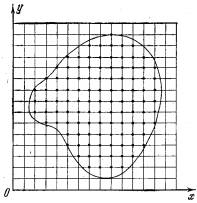
Rys. 1
Konstrukcja siatki z krokiem h i wybór punktów „testowych” na węzłach siatki w celu przybliżonego określenia najmniejszej wartości funkcji dwóch zmiennych. i użyj tych informacji do rozwiązania problemu. W innych przypadkach nie ma formuły dla funkcji celu i istnieje tylko możliwość określenia jej wartości w dowolnym punkcie rozpatrywanego regionu (za pomocą obliczeń, w wyniku eksperymentu itp.). W takich zadaniach, w procesie rozwiązywania, możemy faktycznie znaleźć wartości funkcji celu tylko w skończonej liczbie punktów i zgodnie z tą informacją konieczne jest w przybliżeniu ustalenie jego najmniejszej wartości dla całego regionu. Naturalnie, wielowymiarowe problemy są bardziej złożone i czasochłonne niż problemy jednowymiarowe i zazwyczaj trudności w ich rozwiązywaniu rosną wraz ze wzrostem wymiarów. Abyś mógł lepiej to odczuć, weźmy najprostszą w swojej koncepcji przybliżoną metodę znalezienia najmniejszej wartości funkcji, która została już omówiona dla problemów jednowymiarowych w. Rozpatrujemy rozpatrywany region siatką z krokiem h (rys. 1) i określamy wartości funkcji w jego węzłach. Porównując uzyskane liczby ze sobą, znajdujemy najmniejszą spośród nich i przyjmujemy ją w przybliżeniu dla najmniejszej wartości funkcji dla całego regionu. Jak powiedzieliśmy powyżej, ta metoda jest używana do rozwiązywania problemów jednowymiarowych. Czasami jest także używany do rozwiązywania problemów dwuwymiarowych, rzadziej trójwymiarowych. Jednak w przypadku problemów o wyższym wymiarze jest to praktycznie nieodpowiednie z powodu zbyt długiego czasu wymaganego do obliczeń. Rzeczywiście, załóżmy, że funkcja celu zależy od pięciu zmiennych, a domeną definicji jest sześciowymiarowa kostka, którą dzielimy na 40 części podczas budowania siatki. Wtedy całkowita liczba węzłów siatki wyniesie 415 ~ 108 . Niech obliczenie wartości funkcji w jednym punkcie wymaga 1000 operacji arytmetycznych (jest to trochę dla funkcji pięciu zmiennych). W tym przypadku łączna liczba operacji wyniesie 1011. Jeśli mamy komputer z prędkością 1 miliona operacji na sekundę, wykonanie tego zadania zajmie 105 sekund, co jest więcej niż dniem ciągłej pracy. Dodanie innej niezależnej zmiennej zwiększy ten czas 40 razy. Ocena pokazuje, że w przypadku dużych problemów optymalizacyjnych ciągła metoda wyszukiwania jest nieodpowiednia. Czasami ciągłe wyszukiwanie jest zastępowane wyszukiwaniem losowym. W tym przypadku punkty siatki nie są wyświetlane w rzędzie, ale w kolejności losowej. W rezultacie wyszukiwanie najmniejszej wartości funkcji celu jest znacznie przyspieszone, ale traci swoją niezawodność.
Metoda spadku współrzędnych.
Załóżmy, że musisz znaleźć najmniejszą wartość funkcji celu u = f (M) = f (x 1 , x 2 , ... , xn). Tutaj M oznacza punkt n-wymiarowej przestrzeni o współrzędnych x 1 , x 2 ,. . . , xn: M = (x 1 , x 2 , ... , xn). Wybierz punkt początkowy M 0 = ( x 10 , x 20 , ..., xn0) i rozważ funkcję f dla stałych wartości wszystkich zmiennych z wyjątkiem pierwszej: f ( x 1 , x 20 , x 30 , ... , xn0 ). Następnie zmienia się w funkcję jednej zmiennej x 1 . Zmieniając tę zmienną, przesuniemy się od punktu początkowego x 1 = x 10 w kierunku funkcji malejącej, aż osiągniemy minimum przy x 1 = x 11 , po czym zacznie się zwiększać. Punkt ze współrzędnymi ( x 11 , x 20 , x 30 , ..., xn0 ) jest oznaczony przez M 1 , f (M0) > = f (M 1 ). Naprawiamy teraz zmienne: x 1 = x 11 , x 3 = x 30 ,. . . , xn = xn0 i rozważ funkcję f jako funkcję jednej zmiennej x 2 : f (x 11 , x 22 , x 30 ..., xn0). Zmieniając x 2 , ponownie przesuniemy się od wartości początkowej x2 = x20 w kierunku funkcji malejącej, aż osiągniemy minimum przy x2 = x 21. Punkt o współrzędnych { x 11 , x 21 , x 30 . . . xn0 } oznaczamy M 2, z f (M1) > = f (M 2 ).
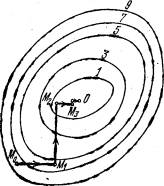
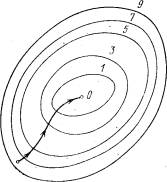
Rys. 2. Poszukiwanie najmniejszej wartości funkcji przy użyciu metody zejścia współrzędnych.
Wykonujemy tę samą minimalizację funkcji celu w odniesieniu do zmiennych x 3 , x 4 ,. . . xn. Po osiągnięciu zmiennej xn ponownie wracamy do x 1 i kontynuujemy proces. Ta procedura w pełni uzasadnia nazwę metody. Z jego pomocą konstruujemy ciąg punktów M 0, M 1, M 2 ,. . . , co odpowiada monotonicznej sekwencji wartości funkcji f (M0) > = f (M 1 ) > = f (M 2 ) > = ... Wycinając ją w pewnym kroku k, możemy w przybliżeniu przyjąć wartość funkcji f (Mk) jako jej najmniejszą wartość w rozważany obszar. Zauważ, że ta metoda zmniejsza zadanie znalezienia najmniejszej wartości funkcji kilku zmiennych w wielu rozwiązaniach problemów optymalizacji jednowymiarowej. Jeśli funkcja celu f (x 1 , x 2 , ..., xn) jest podana przez formułę jawną i jest różniczkowalna, możemy obliczyć jej pochodne cząstkowe i wykorzystać je do określenia kierunku spadku funkcji w każdej zmiennej i poszukać odpowiednich minimów jednowymiarowych. W przeciwnym razie, gdy nie ma wyraźnej formuły dla funkcji celu, problemy jednowymiarowe powinny być rozwiązane przy użyciu metod jednowymiarowych. Na rys. 2 pokazuje linie poziomu pewnej funkcji dwóch zmiennych u = f (x, y). Wzdłuż tych linii funkcja zachowuje stałe wartości równe 1, 3, 5, 7, 9. Trajektoria znalezienia jej najmniejszej wartości, która jest osiągnięta w punkcie O, jest pokazana za pomocą metody współrzędnych zejścia. Należy wyraźnie zrozumieć, że figura służy jedynie do zilustrowania metody. Kiedy zaczynamy rozwiązywać prawdziwy problem optymalizacji, z pewnością nie mamy takiego obrazu zawierającego gotową odpowiedź. Załóżmy, że chcesz rozwiązać problem (2):
f (x) -> min, x ORn. (2)
W przestrzeni dwuwymiarowej R2. Rozwiązanie problemu (2) metodą współrzędnych zejścia, zwaną inaczej metodą Gaussa - Seidla, jest produkowane według następującego ogólnego schematu.
Dowolnie wybierz punkt początkowy x (0) z domeny definicji funkcji f (x). Przybliżenia x (k) są określane przez relacje (3):
x (k + 1) = x (k) + t (k) s (k) (k = 0,1,2, ...),
gdzie wektor kierunkowy zejścia s (k) jest wektorem jednostkowym, który pokrywa się z pewnym kierunkiem współrzędnych (na przykład, jeśli S (k) jest równoległy do x1, to S (k) = {1,0,0, ..., 0} jeśli jest równoległy do x2, to S (k) = {0, 1, 0, ..., 0} itd.); t (k) jest rozwiązaniem problemu minimalizacji jednowymiarowej:
f (x (k) + ts (k)) -> min, t OR1, (k = 0,1,2, ...),
i można to określić w szczególności metodą skanowania.
Szczegółowa implementacja ogólnego schematu w dwuwymiarowym przypadku R2 podaje trajektorie zbliżania się do punktu x * za pomocą metody zejścia współrzędnych składającej się z ogniw polilinii łączącej punkty x (k), x ~ (k), x (k + 1) (k = 0, 1, 2)) (rys. 2). Gdy k = 0, w oparciu o punkt początkowy x (0) = (x1 (0), x2 (0)) , znajdź punkt x ~ (0) = (x1 ~ (0), x2 (0)), minimum pierwszej funkcji zmienna f (x1, x2 (0)); oraz f (x ~ (0)) <= f (x (0)), a następnie znajdujemy minimalny punkt x (1) funkcji f (x1 ~ (0), x2) wzdłuż drugiej współrzędnej. Następnie wykonaj następny krok obliczeniowy, gdy k = 1. Zakłada się, że punktem wyjścia obliczeń jest x (1). Ustalenie drugiej współrzędnej punktu x (1), znajdź minimalny punkt x ~ (1) = (x1 ~ (1), x2 (1)), funkcje f (x1, x2 (1)) jednej zmiennej x (1); ponadto f (x ~ (1)) <= f (x (1)) <= f (x (0)). Punkt x (2) uzyskuje się przez minimalizację funkcji celu f (x1 ~ (1), x2), ponownie wzdłuż współrzędnej x2, ustalając współrzędną x1 ~ (1), punkty x (1) itd.
Warunkiem zakończenia procedury obliczeniowej w przypadku osiągnięcia określonej dokładności e może być nierówność
|| x (k + 1) - x (k) || <e (4)
Schemat blokowy wyszukiwania minimum funkcji dwóch zmiennych metodą zejścia ze współrzędnych.
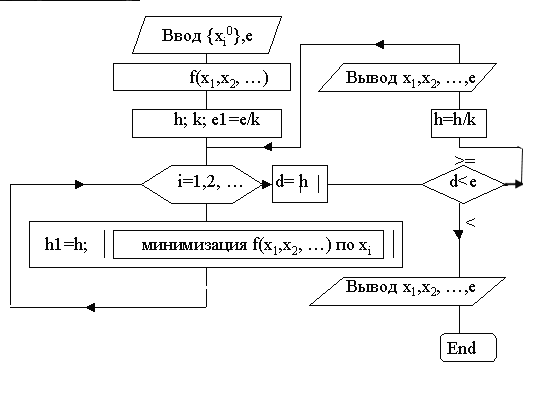
Metoda gradientu zejścia.
Rozważmy funkcję f, rozważając definitywność, która zależy od trzech zmiennych x, y, z. Obliczamy jego pochodne cząstkowe df / dx, df / du, df / dz i tworzymy z nimi wektor, który nazywamy gradientem funkcji:
grad f (x, y, z ) = df (x, y, z) / dx * i + df (x, y, z) / dy * j + df (x, y, z) / dg * k.
Tutaj i , j, k są wektorami jednostkowymi równoległymi do osi współrzędnych. Pochodne cząstkowe charakteryzują zmianę funkcji f dla każdej zmiennej niezależnej oddzielnie. Wektor gradientu utworzony za ich pomocą daje ogólne wyobrażenie o zachowaniu funkcji w sąsiedztwie punktu ( x, y, z). Kierunek tego wektora jest kierunkiem najszybciej rosnącej funkcji w danym punkcie. Kierunek przeciwny do niego, nazywany często anty-gradientem, jest kierunkiem najszybszej funkcji malejącej. Moduł gradientu
(| grad (x, y, z) |) 2 = ( df / dx (x, y, z)) 2 + (df / dy (x, y, z)) 2+ (df / dg (x, y , z)) 2
określa szybkość wzrostu i spadku funkcji w kierunku gradientu i anty-gradientu. Dla wszystkich innych kierunków szybkość zmiany funkcji w punkcie (x, y, z) jest mniejsza niż wielkość gradientu. Podczas przechodzenia z jednego punktu do drugiego zmienia się zarówno kierunek gradientu, jak i jego moduł. Pojęcie gradientu jest naturalnie przenoszone na funkcje dowolnej liczby zmiennych. Przejdźmy do opisu metody gradientowego zniżania. Jego główną ideą jest przejście do minimum w kierunku najszybszej funkcji malejącej, która jest określana przez anty-gradient. Ten pomysł jest realizowany w następujący sposób. Wybieramy punkt początkowy w jakiś sposób, obliczamy w nim gradient danej funkcji i robimy mały krok w przeciwnym kierunku, przeciw-gradientowym. W rezultacie dojdziemy do punktu, w którym wartość funkcji będzie mniejsza niż oryginał. W nowym punkcie powtarzamy procedurę: ponownie obliczmy gradient funkcji i zrobimy krok w przeciwnym kierunku. Kontynuując ten proces, będziemy poruszać się w kierunku malejącej funkcji. Specjalny wybór kierunku ruchu na każdym kroku pozwala nam mieć nadzieję, że w tym przypadku podejście do najmniejszej wartości funkcji będzie szybsze niż w metodzie zejścia ze współrzędnych. Metoda gradientu zniżania wymaga obliczenia gradientu funkcji celu w każdym kroku. Jeśli jest określony analitycznie, to zwykle nie stanowi problemu: dla pochodnych cząstkowych, które definiują gradient, można uzyskać formuły jawne. W przeciwnym razie pochodne cząstkowe we właściwych punktach muszą być obliczone w przybliżeniu, zastępując je odpowiednimi relacjami różnicowymi:
dx ~ ( df ~ f (x1, ..., xi + Dxi, ..., xn) - f (x1, ..., xi, ..., xn) ) / D xi
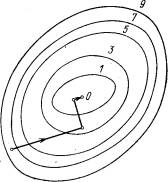
Zauważ, że przy takich obliczeniach Dxi nie można wziąć za mało, a wartości funkcji należy obliczyć z wystarczająco wysokim stopniem dokładności, w przeciwnym razie przy obliczaniu różnicy Df (x1, ..., xi + Dxi, ..., xn) - f (x1 , ..., xi, ..., xn) popełniony zostanie duży błąd. Na rys. 3 przedstawia linie poziomu tej samej funkcji dwóch zmiennych u = f (x, y), jak na Rys. 2, a trajektoria poszukiwania jej minimum jest pokazana za pomocą metody gradientu zniżania.
Porównanie rys. 2 i 3 pokazują, o ile bardziej efektywna jest metoda gradientu zniżania.
Rys. 3. Wyszukaj najmniejszą wartość funkcji za pomocą metody gradientu zniżania
Metoda najbardziej stromego spadku gradientu.
Obliczanie gradientu na każdym kroku, który pozwala cały czas poruszać się w kierunku najszybszego spadku funkcji celu, może jednocześnie spowolnić proces obliczeniowy. Faktem jest, że obliczenie gradientu jest zwykle znacznie bardziej skomplikowaną operacją niż obliczenie samej funkcji. Dlatego często używają modyfikacji metody gradientowej, zwanej metodą najszybszego zejścia.
Rys. 4. Wyszukaj najmniejszą wartość funkcji przy użyciu metody najszybszego zniżania
Zgodnie z tą metodą, po obliczeniu w punkcie początkowym gradientu, funkcje w kierunku antyradientu nie są małym krokiem, ale poruszają się tak długo, jak funkcja maleje. Po osiągnięciu minimalnego punktu w wybranym kierunku, gradient funkcji jest ponownie obliczany i opisana procedura jest powtarzana. W tym przypadku gradient jest obliczany znacznie rzadziej, tylko przy zmianie kierunku ruchu.
Na rys. 4 przedstawia trajektorię poszukiwania najmniejszej wartości funkcji celu metodą najszybszego zejścia. . Wybrana funkcja jest taka sama jak na ryc. 2, 3. Chociaż trajektoria prowadzi do celu, nie jest tak szybka jak na ryc. 3, oszczędność czasu komputera z powodu rzadszego obliczania gradientu może być dość znaczna.
/ źródło informacji: http://school-sector.relarn.ru/dckt/projects/optim/index.htm
Przykład:
Pobierz plik MathCad (aby zoptymalizować inną funkcję, musisz zmienić tylko wzór f (x1, x2): = (x1 + 1) 4+ (x2 + 1) 4+ (x1 + 1) 2+ (x2 + 1) 2 do tego, którego potrzebujesz; zobacz odpowiedź na końcu dokumentu.)


