
- Как работает индексация в поисковых системах (очень быстро)
- Что такое скрытая семантическая индексация
- Теории LSI применялись к поисковым системам в прошлом
- Не стоит недооценивать синонимы
- Документ 1
- Первое рассмотрение:
- Второе соображение:
- Как определить связанные термины
Наша команда-партнер Artmisto
 Сегодня они спросили меня, что такое LSI. На самом деле в своих статьях я часто говорю о БИС, даже в последней интервью с 8 SEO-экспертами эта аббревиатура всплыла, но я никогда не объяснял значение в деталях. Я взял мяч и решил закончить эту статью, которая была в наличии слишком долго. Прежде чем углубляться в детали, имеет смысл понять, почему мы говорим о LSI.
Сегодня они спросили меня, что такое LSI. На самом деле в своих статьях я часто говорю о БИС, даже в последней интервью с 8 SEO-экспертами эта аббревиатура всплыла, но я никогда не объяснял значение в деталях. Я взял мяч и решил закончить эту статью, которая была в наличии слишком долго. Прежде чем углубляться в детали, имеет смысл понять, почему мы говорим о LSI.
Концепция LSI тесно связана с концепцией индексации данных ...
Как работает индексация в поисковых системах (очень быстро)
В прошлом LSI использовался для внутреннего поиска в архивах и базах данных. Когда пользователь искал слово, поисковая система проверяла наличие документов в этом индексе, которые содержали данное слово. Документ может содержать термин или не содержать его. Все документы, которые не включали термин, были отложены, в то время как документы, которые содержали термин, были переданы в систему, которая их заказала (ранжирование). Каждый документ был независим от других, корреляции между несколькими документами не рассчитывались и оценивались только по их содержанию.
Техника LSI улучшила процесс индексации документов: в дополнение к записи слов, содержащихся в документе, этот метод проверяет содержимое по всему миру и пытается найти другие документы, содержащие общие наборы слов. LSI считает два документа семантически близкими, если у них много общих ключевых слов , и считает, что они семантически отдалены, если у них мало общих слов.
Когда поиск выполнялся в базе данных, индексированной с помощью метода LSI, поисковая система возвращала документ, который считался наиболее близким семантически говорящим в ответ на запрос.
Два документа могут быть очень близки семантически даже без общих терминов , LSI не нужно точное совпадение, чтобы найти полезные результаты, и, честно говоря, даже не нужно понимать значение этих терминов .
Из этого первого абзаца вы уже должны были определить область, в которой работает LSI, то есть синонимы .
Что такое скрытая семантическая индексация
Концепция LSI далека от недавней, фактически она впервые обсуждалась в 1960-х годах, а первый зарегистрированный патент датируется 1989 годом. Латентная семантическая индексация (LSI) - это метод индексации и поиска информации, в котором используется методика. называть математику разложение по сингулярным числам (SVD) для определения закономерностей в отношениях между словами и понятиями, содержащимися в документе.
LSI основана на принципе, что слова, используемые в одном и том же контексте, имеют одинаковое значение. Ключевой особенностью LSI является способность извлекать концепцию, выраженную в тексте, путем создания ассоциаций с терминами, встречающимися в документах, имеющих отношение к аналогичным контекстам.
Изучение LSI означает, что латентная семантическая индексация с годами привела к появлению более сложных и сложных функций, используемых для индексации веб-документов, интересным предметом в этом смысле является, например, вероятностная LSI.
Теории LSI применялись к поисковым системам в прошлом
Техника LSI пытается выйти за рамки концепции точного соответствия , то есть точного соответствия между запросом и результатом, модель создает ассоциации для семантических значений, поэтому также между различными терминами, но синонимами или коррелятами.
Теоретически: чем больше релевантных и релевантных терминов содержит статья, тем больше будет значение в соответствии с логикой БИС.
Хотя LSI не используется Google для индексации веб-документов, концепция этой функции может помочь вам написать более релевантные документы благодаря изучению ключевых слов, семантически близких к теме страницы.
Не стоит недооценивать синонимы
LSI и ключевые слова
Во всех стратегиях SEO большое внимание всегда уделялось правильному написанию тега заголовка и заголовков, в частности H1. Даже альтернативные теги, слова, выделенные жирным шрифтом или курсивом, важны, но их недостаточно для надежного и эффективного SEO. Для этого очень важно знать, как работает LSI, поскольку она может влиять на ключевые слова, по которым проиндексирован ваш сайт.
Когда контент содержит соответствующие синонимы ключевых слов, используемых в теге заголовка, поисковые системы, как правило, лучше оценивают страницу, чем контент, который не содержит синонимов. Причина проста: содержание более четкое (избегает возможных недоразумений), полно и актуально для предмета. Использование синонимичных терминов помогает поисковым системам более точно идентифицировать тему и делает контент более актуальным .
Давайте посмотрим на очень простой пример:
Документ 1
- заголовок тега: Apple
- повторяющиеся слова: яблоко, груша, абрикос, клубника, фрукты
Документ 2
- заголовок тега: Apple
- повторяющиеся слова: Стив, iPhone, Mac, Джобс
Примечание. Приведенный пример намеренно прост, чтобы сделать теорию, лежащую в основе метода БИС, простой и понятной. Оптимизация сложных текстов с конкурентоспособными ключевыми словами намного сложнее, требуя времени и внимания при выборе наиболее подходящих связанных терминов и определении наилучших позиций для позиционирования ключевых слов.
Первое рассмотрение:
Хотя названия двух документов идентичны, LSI помогает поисковым системам понять, что обсуждаемые темы действительно очень разные, в первом случае мы говорим об яблоке как о фрукте, а во втором - как о компании. Соответствующие термины и синонимы помогают интерпретировать содержание, чтобы избежать недоразумений и предоставить наиболее релевантные возможные результаты.
Второе соображение:
Учитывая два содержания, которые говорят о фруктах, в частности о яблоках, содержание, которое включает синонимы, альтернативные, релевантные и семантически релевантные термины, будет иметь большее значение в глазах Google, чем в плохом содержании этих элементов.
Как определить связанные термины
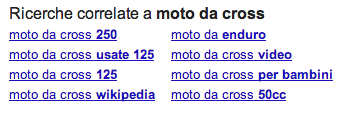
Похожие запросы
Скрытое семантическое индексирование - это не наука, это простой здравый смысл и правильное использование слов посредством семантического анализа. Вот несколько простых рекомендаций:
- Если заголовок страницы «Научиться ездить», убедитесь, что ваша статья рассказывает о мотоциклах :)
- Не злоупотребляйте одними и теми же ключевыми словами в контенте, это может показаться наполнением ключевых слов, которое не нравится поисковым системам ...
- Никогда не используйте автоматические инструменты для вращения предметов. Результаты очень часто низкого качества, и Google это замечает!
- Если у вас есть статьи для вашего сайта, написанные сторонними компаниями или копирайтерами, убедитесь, что они знают, что пишут, и делают это правильно.
- Всегда проверяйте консоль поиска Google, чтобы увидеть, какие ключевые слова генерируют ценный трафик для вашего сайта. Сконцентрируйтесь на этих словах, генерирующих свежий и интересный контент (найдите эту информацию в меню «Поисковый трафик», а затем в «Поисковом запросе»)
- Получите лучшие релевантные ключевые слова от Google : запустите определенный поиск и прокрутите до конца страницы результатов, вы увидите окно под названием «Похожие запросы», в котором перечислены некоторые похожие запросы, выполненные пользователями.
- Используйте Планировщик ключевых слов AdWords, чтобы найти идеи и ключевые слова, относящиеся к теме, которую вы хотите написать, и, возможно, даже мою инструмент связанного ключевого слова
- Используйте словарь синонимов :)
Методы латентного семантического индексирования - это не уловка для обмана поисковых систем, а скорее способ повысить релевантность контента посредством использования соответствующих терминов.


