
- Семантический поиск или поиск статистической информации?
- Как работает Word2Vec
- Как поисковые запросы могут быть автоматически классифицированы
- Семантическое понимание как одна из целей Google
Наша команда-партнер Artmisto
Такие вехи, как График знаний, Hummingbird и RankBrain, помогли Google сделать несколько шагов к тому, чтобы стать совершенной поисковой системой. Статистика, семантические теории и структуры, а также машинное обучение играют важную роль. В последнем разделе « Развертывание секретов SEO» приглашенный автор Олаф Копп рассматривает аспекты семантики и машинного обучения в поиске Google.

В последнем выпуске « Развертывание секретов SEO» я изложил свой взгляд на как Google интерпретирует поисковые запросы и пользователь намерения за ними. Теперь пришло время взглянуть на то, как Google делает такую хорошую работу по повышению точности поиска.
Семантический поиск или поиск статистической информации?
У меня было много жарких споров (цивилизованных дебатов?) С коллегой по SEO Йенсом Фолдратом о том, действительно ли Google является семантической поисковой системой.
Результаты, которые Google представляет своим пользователям, безусловно, создают впечатление, что гигант поисковой системы обладает глубоко развитым семантическим пониманием в отношении поисковых запросов и документов. Однако многое из того, что приводит к этому появлению, основано на статистических методах, а не на каком-либо подлинном семантическом понимании. Но благодаря семантическим структурам в сочетании со статистикой и машинным обучением Google теперь может приблизиться к семантическому пониманию.
«Например, мы находим, что полезные семантические отношения могут быть автоматически извлечены из статистики поисковых запросов и соответствующих результатов, или из накопленного свидетельства текстовых шаблонов и форматированных таблиц на основе Интернета, в обоих случаях без необходимости каких-либо аннотированных вручную данных. " Источник: Неоправданная эффективность данных, IEEE Computer Society, 2009
Как работает Word2Vec
Чтобы продемонстрировать это более четко, я кратко введу работу статистического анализа текста. Google использует анализ векторного пространства для оценки релевантности и идентификации отношений. Векторное пространство состоит из отдельных точек данных, которые могут быть связаны через векторы в векторном пространстве. Угол между векторами говорит нам о сходстве и / или отношениях между точками данных. Чем больше угол, тем меньше сходство. Чем меньше угол, тем больше сходство. Например, для анализа основных компонентов в векторном пространстве создается вектор поиска из поискового запроса и всех доступных релевантных документов. Для этого так называемого процесса «встраивания слов» Google использует Word2vec.
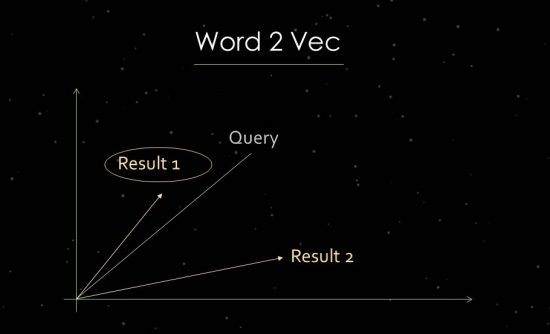
Использование близости точек данных друг к другу позволяет показать семантические связи между ними. Как правило, векторы создаются для поисковых запросов и документов, которые можно размещать относительно друг друга. Другое использование - создание векторов из документа и терминов внутри него, чтобы определить его концепцию или тему. Также было бы возможно сформировать векторы из таких лиц, как люди, бренды, компании или темы.
Чтобы использовать анализ векторного пространства, сначала необходимо проиндексировать документы и сопоставить их с концепциями или тематическими областями, которые затем составляют соответствующий тематический корпус. Процесс для выполнения этого шага - скрытое семантическое индексирование (LSI), которое позволяет создавать векторные пространства, которые обеспечивают наилучшие результаты с точки зрения точности и отзыва. Используя этот метод, также можно выполнить семантическую классификацию или кластеризацию терминов, связанных с темой.
Как поисковые запросы могут быть автоматически классифицированы
В прошлом основной проблемой было отсутствие масштабируемости, поскольку поисковые запросы приходилось классифицировать вручную. Это слова бывшего вице-президента Google Мариссы Майер по этому вопросу из интервью 2009 года:
«Когда люди говорят о семантическом поиске и семантической сети, они обычно имеют в виду нечто очень ручное, с картами различных ассоциаций между словами и тому подобным. Мы думаем, что вы можете достичь гораздо лучшего уровня понимания с помощью сопоставления с образцом данных, создавая крупномасштабные системы. Вот так работает мозг. Вот почему у вас есть все эти нечеткие связи, потому что мозг постоянно обрабатывает много-много данных… Проблема в том, что язык меняется. Веб-страницы меняются. Как люди выражают себя, меняются. И все эти вещи имеют значение с точки зрения того, насколько хорошо применяется семантический поиск. Вот почему лучше иметь подход, основанный на машинном обучении, который изменяет, повторяет и реагирует на данные. Это более надежный подход. Это не значит, что семантический поиск не участвует в поиске. Просто для нас мы предпочитаем сосредоточиться на вещах, которые могут масштабироваться. Если бы мы могли предложить решение для семантического поиска, которое могло бы масштабироваться, мы были бы очень рады этому. На данный момент мы видим, что многие наши методы приближаются к интеллекту семантического поиска, но делают это другими способами ». Источник: http://www.pcworld.com/article/181874/article.html
Многое из того, что мы называем семантическим пониманием, когда мы говорим о том, что Google определяет значение поискового запроса или документа, основано на статистических методах, таких как анализ векторного пространства, или методах статистического анализа текста, таких как TF-IDF. Строго говоря, это не основано на подлинной семантике. Но результаты очень близки к семантическому пониманию. Более широкое применение машинного обучения - и более подробный анализ, который это позволяет - значительно упрощает семантическую интерпретацию поисковых запросов и документов.
Семантическое понимание как одна из целей Google
Одной из самых важных целей Google является достижение семантического понимания в отношении поисковых терминов и проиндексированных документов для отображения более релевантных результаты поиска , Семантическое понимание существует, когда (поисковый) запрос и содержащиеся в нем термины могут быть поняты однозначно. Однозначное толкование часто затрудняется запросами, включающими термины с несколькими значениями, термины, неизвестные системе, неясные выражения, индивидуальное понимание и т. Д.
Для облегчения понимания проводится анализ используемых слов, их порядка и контекста их темы, времени и места. Машинное обучение и / или RankBrain позволяют Google использовать кластерный анализ для автоматического создания новых классов и назначения им поисковых запросов. Это не только устанавливает высокий уровень детализации, но также создает масштабируемость и повышает производительность. Создание новых векторных пространств для анализа векторного пространства также стало возможным.
Таким образом, статистика в сочетании с машинным обучением дает все более семантическую интерпретацию, которая очень близка к семантическому пониманию поисковых запросов и документов. Google хочет воссоздать по-настоящему семантический поиск с помощью статистических методов и машинного обучения. Кроме того, центральным элементом современного Google поисковый движок График знаний также основан на семантических структурах.
В третьей части этой серии статей о семантике и машинном обучении Google Олаф Копп рассмотрит основы семантики: графики, сущности и онтологии.
Семантический поиск или поиск статистической информации?Семантический поиск или поиск статистической информации?
Ивилизованных дебатов?


