
- Что такое бюджет сканирования и почему это важно?
- Что такое ловушка для пауков и как ее исправить?
- 1. Бесконечная календарная ловушка
- Как определить ловушку бесконечного календаря
- Как исправить ловушку бесконечного календаря
- 2. Бесконечная ловушка URL
- Как обнаружить бесконечную ловушку URL
- Как исправить бесконечную ловушку URL
- 3. Ловушка идентификатора сеанса
- Как определить ловушку идентификатора сеанса
- Как исправить ловушку идентификатора сессии
- 4. Грановитая навигационная ловушка
- Как определить ограненную ловушку навигации
- Как исправить ограненную ловушку навигации
- Итак, надоедливые ловушки для гусеничных машин были удалены; что теперь?!
Наша команда-партнер Artmisto
Люк Фицджеральд 30 мая 2016

Одна из наиболее сложных и, возможно, наименее понятных проблем, с которыми мы столкнулись здесь в команде Wolfgang Digital SEO за последние 12 месяцев, - это рост известности, частоты и общего хаоса, вызванного страшной «ловушкой пауков». или «гусеничная ловушка» как их иногда называют ,
Ловушка для пауков - это то, что веб-мастерам следует избегать любой ценой, поскольку это, по сути, смертельный удар по способности вашего сайта сканироваться и индексироваться, что, в свою очередь, негативно влияет на общую органическую видимость, рейтинги и, в конечном счете, способность вашего сайта приносить доход. ; это очень важно, когда контекстуализируется как таковой!
Таким образом, для того, чтобы у вас было четкое представление о потенциальном воздействии ловушки для пауков, важно, чтобы мы дали представление о том, что такое ловушка для пауков, как ее идентифицировать и как ее диагностировать, но до того, как мы соткнем эту конкретную ловушку. веб (простите за паутину!), давайте сделаем шаг назад и разберемся с фундаментальной причиной, по которой все это важно для нас как оптимизаторов веб-сайтов, владельцев бизнеса и маркетологов; все зависит от концепции бюджета сканирования и от того, как вы можете влиять на производительность веб-сайта в контексте поддержания эффективности сканирования посредством эффективного управления URL-адресами.
Что такое бюджет сканирования и почему это важно?
Google и другие поисковые системы вложили значительный капитал в создание этих замечательных поисковых систем, которые укоренились в нашей повседневной жизни; Прошли те времена, когда мы отряхнули старую Британскую энциклопедию за авторитетные ответы на наши ежедневные запросы или за невинные ранние дни интернета, когда просто спрашивали Дживса и надеялись, что он подал нам удовольствие! Поисковые системы - это большой бизнес, и с SEO потратил до 80 млрд долларов в одних только США к 2020 году, скорее всего, они здесь, чтобы остаться, в той или иной форме.
Поскольку постоянно совершенствующийся алгоритм Google находится на переднем крае всего, что мы в SEO-индустрии стараемся выстроить вокруг себя, мы можем предположить, что Big G поддерживает значительные расходы на содержание этого огромного зверя, управляемого Ранкбрейном. Излишне говорить, что боты / сканеры / пауки, используемые Lord Googlebot для сканирования наших сайтов, индексирования нашего контента и, в конечном итоге, отображения их для нашей целевой аудитории, стоят денег для запуска. Размещенные в обширных серверных сетях, разбросанных по всему земному шару, финансовые затраты связаны с физическим предоставлением полосы пропускания, расходуемой этими пауками, когда они постоянно сканируют сеть.

По сути, если веб-сайт не оптимизирован для обеспечения эффективного доступа паука к его инфраструктуре, паук неизбежно достигнет момента времени, когда он достигнет выделенной пропускной способности для данного сайта и перейдет на следующий веб-сайт при сканировании. график, а не бездельничать на одном и том же сайте, надеяться, что он найдет выход из множества проблем, прежде чем выйти на другую сторону с четким пониманием того, что он только что отсканировал.
Естественно, если существует проблема, из-за которой паук не может выполнить поставленную задачу и прекращает сканирование сайта при достижении бюджета сканирования, то уязвимый сайт в некотором смысле можно считать «менее оптимальным» в глазах и, по сути, может быть понижен (если речь идет о ранжировании сайта, скажем, сайта-конкурента, к которому у сканера нет проблем с доступом), в результате.
Кроме того, если у веб-сайта есть серьезные проблемы со сканированием, то некоторые очень важные продукты, категории или информационные страницы могут никогда не увидеть свет в результатах поисковой выдачи, если паук не смог связаться с ними с самого начала.
Чтобы описать эту концепцию немного странно, рассмотрим следующий сценарий:
Вы гуляете по новому многоэтажному торговому центру, просматриваете первые несколько магазинов, решаете, какие магазины вам нравятся и о которых вы могли бы рассказать своим друзьям, а также какие из них вы не захотите посетить снова.
И вдруг, как только вы почувствуете это место, ставят жалюзи на магазины, вы не можете идти дальше в этот замечательный новый торговый комплекс, охранники блокируют вам путь к входу, и у вас нет представьте себе, что находится в оставшихся магазинах или как вы можете потратить свой бюджет на запланированную поездку за покупками.
Естественно, вы делаете билайн для ближайшего выхода, возможно, с кислым вкусом во рту, с меньшей вероятностью возвращения, и все еще не понимая, что за ставнями, которых вы так неожиданно достигли. Вы приносите свои с трудом заработанные деньги в соседний магазин, который встречает вас с распростертыми объятиями, отвечает всем вашим покупательским потребностям, и вы рассказываете своим друзьям о том, как великолепно это место!
В этом сценарии (на случай, если я уже потерял вас!) Вы являетесь сканером, магазины - это страницы веб-сайта, а ваши друзья - поисковыми запросами; Вы можете догадаться, кто играл роль ловушки для пауков ?! Конечно, эти надоедливые ставни / охранники!
Бюджет сканирования, в его наиболее чистом определении, можно определить как число посещений вашего поискового движка вашим сайтом в течение определенного периода времени, на которое сильно влияет его простота навигации по сайту. Например, если робот Googlebot обычно посещает ваш веб-сайт примерно X раз в месяц, мы можем с достаточной степенью уверенности предположить, что эта цифра является вашим ежемесячным бюджетом сканирования для робота Googlebot, хотя это ни в коем случае не является камнем.
Важно понимать, что предполагаемый бюджет сканирования может со временем меняться. Многие другие факторы, такие как PageRank (тот тип, который Google по-прежнему наиболее определенно использует для внутреннего использования, несмотря на то, что он больше не используется в качестве общедоступной метрики панели инструментов) и нагрузка на хост сервера, также играют роль в бюджете сканирования, как заявили бывшие друзья-оптимизаторы, Мэтт Каттс в откровенном интервью на эту тему с Эриком Энге пару лет назад
Быстрое сканирование веб-журналов или даже с помощью консоли поиска в разделе «Статистика сканирования» поможет вам понять, каким может быть ваш средний бюджет сканирования для Google в данный момент времени.
Вот пример того, как выглядит расчетный бюджет обхода для нашего собственного нового шикарного веб-сайта Wolfgang Digital:
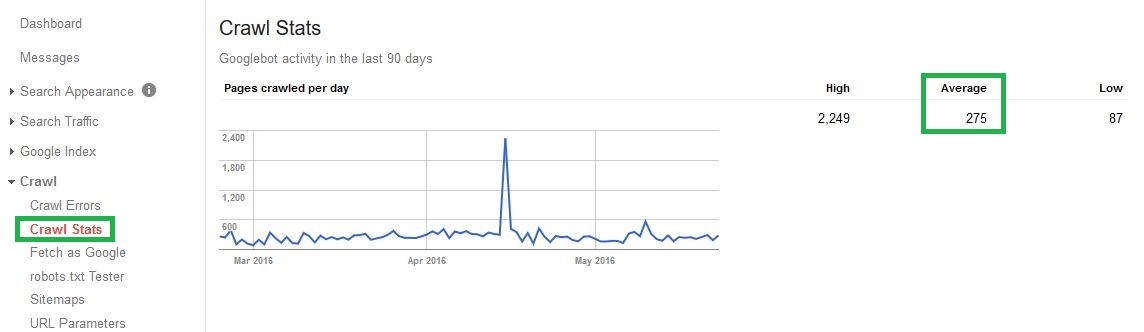
Глядя на приведенную выше статистику, если мы возьмем среднесуточное значение 275 * 30, то мы можем вывести средний месячный бюджет сканирования для этого веб-сайта от Google, равный 8250, то есть теперь у нас есть приблизительная оценка количества страниц, которые мы можем ожидать от Google. , индекс и ранг в течение определенного периода времени.
Если количество активов для обхода (URL), которые мы хотим ранжировать, значительно выше (или ниже), чем эта сумма, это обычно означает, что мы должны смотреть дальше на оптимизацию бюджета сканирования как на приоритетные вопросы с технической точки зрения SEO. К счастью, сейчас все в порядке, но мы регулярно сталкиваемся со сценариями, в которых веб-сайты борются со своим веб-IA, и зачастую первопричину можно определить с помощью простого обхода Screaming Frog, настроенного для эмуляции робота Google.
Суть в том, что если ваш сайт не может быть проиндексирован, он не может быть ранжирован. Не позволяйте обходу бюджета играть роль в том, как паук обращается с вашим сайтом, убедитесь, что вы оптимизируете, чтобы позволить паукам заходить на ваш сайт, посещать то, что важно, и выходить с сайта без каких-либо неопределенных условий, что вы сделали все возможное чтобы сделать это гладким, логичным опытом для них.
Что такое ловушка для пауков и как ее исправить?
Ловушка для пауков, прямо изображенная как необоснованный охранник или неодушевленная шторка наверху, - это в основном то, что мешает пауку зайти на ваш сайт, приятно провести время и уйти, оставив только радостные воспоминания и несколько хороших индексируемых страниц. ранжироваться в поисковой выдаче в сравнении с суровой реальностью попадания в мрачный, бесконечный цикл раздела вашего сайта, который вызывает всевозможные проблемы и в конечном итоге заставляет их сдаваться и двигаться дальше из-за запрограммированных пределов допустимой пропускной способности.

Получив доступ к основным инструментам, необходимым для выполнения сканирования сайта, вы готовы начать анализ сканирования, чтобы определить, существует ли ловушка для пауков на вашем сайте.
Они особенно распространены на сайтах электронной коммерции из-за характера больших проблем управления запасами и причудливых конфигураций фильтрации под управлением UX, но их можно найти практически на любом сайте с динамически обслуживаемым контентом. Большие сайты, естественно, будут выделять большую пропускную способность для пауков поисковых систем, но это не значит, что они менее восприимчивы к попаданию в ловушку, наоборот, если это так. Точно так же меньшие сайты могут быть одинаково затронуты этими проблемами, если они не пресечены в зародыше на ранней стадии.
Иногда ловушка проявляется на очень ранней стадии, когда появляется петля с менее чем половиной сайта.
Вот пример ловушки пауков очень ранней стадии на очень маленьком сайте, когда сканирование попадает на 8-й актив, а затем возвращается назад по URL-адресам 1-7, а затем возвращается к 8 с 6,4% завершения сканирования; это означает, что ошеломляющие 93,6% этого небольшого веб-сайта не сканируются, не индексируются и не ранжируются:

Следующий индекс завершения сканирования иллюстрирует, как выглядит ловушка для пауков среднего уровня: пауки просканировали значительную часть этого большого сайта, поэтому ставка не может идти дальше, фактически оставляя 2/5 этого большого сайта электронной коммерции «на полке» с точки зрения потенциальной видимости сети:

В других случаях он может начаться в самом конце дня, когда почти весь сайт просканирован, однако сканирование просто никогда не закончится из-за постоянного падения сканера по бесконечному циклу, вызванному сложной многогранной конфигурацией навигации или простой ошибкой кодирования.

Это может быть особенно обескураживающим, поскольку, когда вы думаете, что сканирование почти завершено с оставшимися более чем 161 URL-адресами из более чем 40 КБ, оно начинает подниматься вверх около отметки 200 и никогда не опускается ниже отметки 100 к завершению.
Этот вид ловушек, скорее всего, окажет меньшее влияние в том смысле, что просканировано большинство сайтов, но, несомненно, заставит сканеры выглядеть неблагоприятно на рассматриваемом сайте и, возможно, сократит бюджет на сканирование, чтобы избежать выполнения подобных проблем. в будущем ползет. Лучше не оставлять такие вещи на волю случая в надежде, что сканеры посчитают, что все в порядке и будут индексировать большую часть обнаруженного, скажем, давайте пресечем эти ловушки в зародыше и сделаем эффективность сканирования не проблемой раз и навсегда!
Есть четыре основных причины ловушек пауков, с которыми мы столкнулись в последнее время, каждая из которых имеет различную степень сложности как для идентификации, так и для диагностики; давайте начнем с более простых, переходя к подходящим сценариям головной боли для нас, SEO-специалистов (не говоря уже о бедных пауках, которых, я уверен, многие из вас теперь представляют себе как волосатого маленького гугл-твари, направляющего свой путь вниз по сети). к вашему любимому домену!
Если вы лучше разбираетесь в использовании инструментов для сканирования, у вас могут возникнуть острые вопросы, например, «почему это сканирование никогда не закончится?» или «почему дым исходит от моего нового Lenovo?»; Надеемся, что это руководство поможет вам успокоиться и поможет вам найти оптимальный вариант для всех.
1. Бесконечная календарная ловушка
Календарная ловушка, пожалуй, единственная ловушка, которая не является результатом ошибки или серьезного технического контроля со стороны любого разработчика или веб-мастера. Теоретически обслуживаемые страницы являются законными URL-адресами, которые служат конечной цели или функции; единственная проблема заключается в том, что, поскольку время по определению бесконечно, то и любые URL-адреса относятся ко времени!
Как определить ловушку бесконечного календаря
Это, вероятно, самый простой вид ловушки для пауков, чтобы понять, распознать и адресовать, если у вас есть календарь на вашем сайте, который позволяет молодому родителю переходить и потенциально забронировать мероприятие для выпускного бала их новорожденного ребенка, или, что еще хуже, поездки в Диснейленд в 3016, то, скорее всего, ваш сайт имеет ловушку календаря!
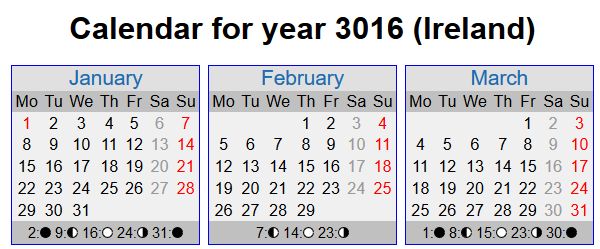
Сканер никогда не достигнет конца этих страниц календаря, если не будет установлена система для управления разумной датой отсечения, которую, конечно, необходимо будет пересмотреть, как только эта дата станет разумной в будущем!
Как исправить ловушку бесконечного календаря
Есть ряд относительно простых исправлений, чтобы гарантировать, что это никогда не будет проблемой для вашего сайта. Использование метатега 'noindex, nofollow' в годах 'сверх разумной даты' является одним из вариантов, в то время как использование файла robots.txt для запрета любых URL-адресов, относящихся к дате, помимо определенного периода времени, является другим вариантом, хотя этот маршрут не является обычным.
Большинство готовых плагинов для календаря Web 2.0 и руководящих принципов по самостоятельной сборке уже созданы с учетом этих соображений, но время от времени появляются на некоторых старых сайтах с множеством других унаследованных проблем. удобное решение для ограничения хоста для ловушек календаря, описанных в архивах JIRA, в случае необходимости.
2. Бесконечная ловушка URL
Бесконечную ловушку URL можно найти практически на любом веб-сайте, и она не разделяет общие черты между секторами промышленности или транзакционными, а не транзакционными доменами; обычно это просто результат неверно сформированного относительного URL или плохо реализованных правил перезаписи URL на стороне сервера.
Как обнаружить бесконечную ловушку URL
Очень редко можно увидеть результаты этой конкретной ловушки в веб-браузере или даже в поисковой выдаче, поскольку они часто зарываются глубоко в IA сайта и часто могут быть причиной того, что какой-то контент выходит за рамки бесконечного URL фактически не индексируется для поиска пользователем. Как правило, они становятся очевидными только при использовании такого инструмента, как превосходная Screaming Frog или Xenu Link Sleuth.
Вы можете сказать, что что-то не так, когда начнете замечать, что а) сканирование попало в камень преткновения и снова зациклилось на нем, как указано выше, и б) некоторые действительно выглядящие в стиле фанк URL-адреса начинают появляться на панели мониторинга сканирования с десятками, сотнями, к нему добавлены даже тысячи сумасшедших каталогов. Вот пример недавнего случая этой точной ловушки, обнаруженной на сайте клиента электронной коммерции:
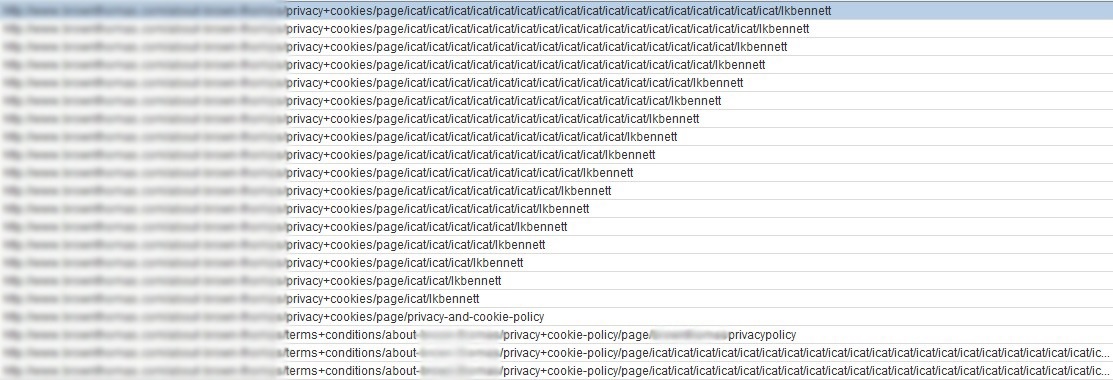
Обратите внимание на отсутствие продолжительной косой черты на относительной ссылке, достаточной для того, чтобы обмануть паука и подумать, что бесконечное количество каталогов обрабатывает этот каталог, таким образом отправляя сканирование в перегрузку по бесконечному циклу URL!
Это лишь одна из многих причин, по которым мы не являемся поклонниками относительных ссылок здесь, в Вольфганге, абсолютные URL-адреса - это порядок дня, но это совсем другая тема для другого дня! У Йоста Йоста де Валька есть подробный пост в блоге, выражающий довольно экстремальный взгляд на относительные URL должно быть запрещено для веб-разработчиков , сославшись на ловушку пауков в качестве одного из ключевых рисков, связанных с их использованием, в то время как у Рут Берр-Ривер есть превосходная пятничная сессия, освещающая в пятницу почему относительные URL могут быть худшим кошмаром SEO ; Стоит посмотреть, чтобы помочь развить дальнейшее понимание этой темы в целом.
Относительно проблем относительного связывания, некоторые другие причины, по которым вы можете встретить бесконечную строку URL-адреса, возникающую в среде обхода, включают плохо настроенные правила перезаписи URL-адреса из предыдущего проекта миграции веб-сайта или некорректные параметры запроса, которые игнорируют большие разделы строки URL-адреса из-за динамическое обслуживание URL-адресов на стороне, например, если кто-то вводит «www.yoursite.com/this-is-a-completely-made-up-url», но сервер все равно возвращает код ответа 200 в рамках обхода вместо 404. Решение для этого остается практически одинаковым по всем направлениям; необходимость в правильно поддерживаемой инфраструктуре управления URL-адресами в сочетании с правильной обработкой кода ответа сервера.
Как исправить бесконечную ловушку URL
Как только вы заметили, что происходит такая ловушка, вы можете использовать функцию сортировки в программе-обходчике для сортировки по длине URL; найдите самый длинный URL, а затем вы найдете корневой источник проблемы, в приведенном выше случае мы смогли выделить виновника как находящегося где-то в исходном коде каталога 'lkbennett'.
Затем нужно проанализировать исходный код рассматриваемой страницы и найти аномалии. Оказывается, что в самом корне этой проблемы с пауком лежит очень простая ошибка; маленькая опечатка в строке 2354 кода в конфигурации относительной ссылки URL:

Учитывая, что на рассматриваемой странице имеется более 1300 ссылок, и любая из них могла быть потенциальной причиной, это была общеизвестная игла в стопке игл, но опытный глаз может обнаружить эти проблемы довольно быстро. Большое облегчение, что это не было намного, намного худшей проблемой; однажды помеченный, это было положено спать в считанные минуты, и сайт снова начал стрелять по всем цилиндрам!
В случае сбоя процесса ручной прополки, есть еще несколько технических способов разрешения ситуации: либо запретить нарушающие параметры в файле robots.txt, либо добавив правила на стороне сервера, чтобы гарантировать, что строки URL с определенным максимальным ограничением строк URL на их. Оба этих подхода требуют определенных навыков программирования, но общая цель состоит в том, чтобы несуществующие URL-адреса правильно обслуживали 404 кода ответа, а не позволяли им отбрасывать их на 200 (ОК) страниц для бесконечного потребления ботов.
Если вам достаточно повезло, что у вас есть доступ к команде разработчиков, обладающих навыками для реализации этих обходных путей, они также должны быть хорошо оснащены для более постоянного решения проблемы, которая привела нас сюда в первую очередь; а именно в форме перестроения или полнофункционального упражнения по перезаписи URL.
3. Ловушка идентификатора сеанса
Паучья ловушка идентификатора сеанса обычно встречается на более крупных веб-сайтах электронной коммерции, где была установлена необходимость более детального отслеживания сеанса пользователя, присвоения канала и перекрестных продаж между установленными SBU без необходимости чрезмерной зависимости от файлов cookie в качестве основного инструмента сбора данных.
Как определить ловушку идентификатора сеанса
Такую ловушку обычно можно довольно быстро найти, просканировав ваш веб-сайт и посмотрев в списке просканированных URL-адресов что-то вроде этого:

Обычно идентифицируемыми признаками ловушки идентификатора сеанса являются появление тегов, таких как «jsessionid», «sid», «affid» или аналогичных, в строках URL-адресов при развертывании сканирования, с теми же идентификаторами, повторяющимися после точки, в которой паук может успешно перейти на следующую строку URL-адреса, содержащую идентификатор.
В других случаях, когда проверенные сайты тестируют новые способы отслеживания пользователей и файлов cookie (без предварительного знания того, как это может повлиять на эффективность сканирования), потенциальная проблема возможной ловушки пауков может быть выявлена в браузере практически мгновенно, если строка постоянного параметра добавлено к ранее нормально выглядящему TLD:

В каждом из этих очень разных случаев использование jsessionid и opt = - это попытки отслеживать сеансы пользователей без использования традиционной модели атрибуции на основе файлов cookie, а не то, что мы когда-либо слишком стремились рекомендовать как склонность к ошибкам настолько высока; мы еще не увидели, что это реализовано без каких-либо серьезных недостатков.
Логика, лежащая в основе реализации отслеживания идентификатора сеанса, заключается в том, что если конкретный URL-адрес, который посетил пользователь, не связан с идентификатором сеанса, то пользователь перенаправляется на ту же версию URL с идентификатором сеанса, добавленным в его конец, согласно приведенному выше примеру «opt =». Если запрошенный URL-адрес имеет присвоенный ему требуемый идентификатор сеанса, то сервер загрузит соответствующую веб-страницу, но он также добавляет идентификатор сеанса к каждой внутренней ссылке на той же странице; это то, где все это начинает распадаться с точки зрения паука, потому что с этого момента может быть и часто происходит что-то не так, и этого достаточно, чтобы мы могли оправдать призыв к этой практике, чтобы избежать ее во всей полноте, где это возможно!
В том-то и дело, что здесь почти всегда есть пара ссылок, которые проскальзывают через сеть, которые неправильно присваиваются конкретному идентификатору сеанса, чтобы этот проект отслеживания работал бесперебойно. Если структура содержит только одну внутреннюю ссылку без соответствующего идентификатора сеанса из-за неправильной реализации, то ссылка будет эффективно генерировать новый идентификатор сеанса каждый раз, когда за ним следуют. Это означает, что из PoV паука он получает новую версию всего сайта, привязанную под совершенно новым идентификатором сеанса каждый раз, когда происходит доступ к этой мошеннической ссылке. Смущены еще? Вообразите, что бедный паук делает из всего этого!
Как исправить ловушку идентификатора сессии
Чтобы диагностировать проблему такого рода во время начального сканирования сайта, может потребоваться сначала исключить ошибочные параметры в самом инструменте сканирования, чтобы можно было успешно завершить сканирование. По мере добавления исключений можно выбирать все больше и больше проблемных параметров до тех пор, пока окончательное сканирование не станет возможным. Это может выглядеть примерно так в приведенном выше примере, чтобы исключить проблемные параметры правил 'opt =', 'so =' и 'returnurl' из обхода Screaming Frog:
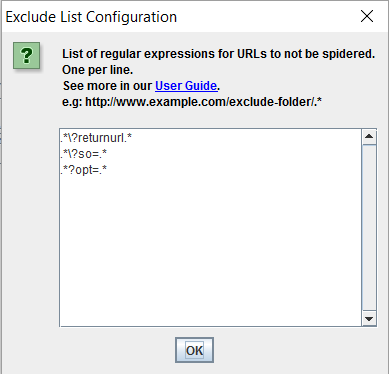
Идеальное решение здесь состоит в том, что эту логику следует полностью удалить с сайта, но если требуется решение о банде, репликация этих исключений в файле robots.txt должна гарантировать, что робот Googlebot и другие пауки поисковой системы теперь могут выйти из ловушки. и начать индексирование некоторых наиболее важных URL, для которых мы хотим, чтобы сайт имел органическую видимость.
Управление параметрами URL-адреса в консоли поиска Google также может помочь в задаче инструктирования робота Google о конкретных способах работы с определенными параметрами, с опциями сканирования, не сканирования или «позволить роботу Google решать» с использованием активных / пассивных правил в раскрывающемся списке. поля доступны рядом с каждым экземпляром параметра.
Однако, как вы заметите, войдя в эту область GSC, вы увидите предупреждение «Используйте эту функцию, только если вы уверены, как работают параметры. Неправильное исключение URL может привести к тому, что многие страницы исчезнут из поиска. Приветствует веб-мастеров по прибытии:
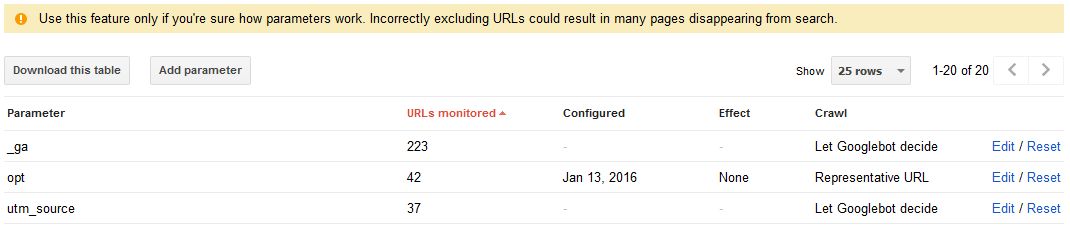
Обращайтесь с этим осторожно, так как это, вероятно, один из самых продвинутых разделов во всем наборе Google для веб-мастеров. Не забудьте прочитать на официальные рекомендации по теме если это кроличья нора, вы стремитесь исследовать глубины.
Если ваш сайт становится жертвой этой проблемы, единственный надежный способ полностью устранить этот вид ловушек для пауков - это полностью удалить каждый экземпляр идентификатора сеанса из всех гиперссылок и всех внутренних правил перенаправления по всему сайту. Необходимо позаботиться о том, чтобы каждый экземпляр был удален, как если бы оставался хотя бы один экземпляр, при сканировании все равно будут генерироваться URL-адреса с потенциально неограниченным числом при достижении точки ошибки в IA.
4. Грановитая навигационная ловушка
Именно эту ловушку для пауков мы нашли наиболее сложной для решения здесь, в штаб-квартире Вольфганга, не только потому, что решение часто сложно реализовать, но и потому, что, теоретически, многогранная навигация является одной из лучших функций UX в любой современной электронной коммерции. Веб-сайт; это позволяет пользователям быстро фильтровать глубоко в структуре меню сайта, чтобы найти то, что они действительно хотят.
Как подчеркнул Clickz в этом великолепном взгляде на как заставить роботов плакать с помощью граненой навигации его присутствие на сайте «является почти повсеместно положительным опытом для людей».
Два наиболее важных преимущества граненой навигации обозначены как:
- Фасеты позволяют пользователям комбинировать выборки, чтобы сосредоточиться на результатах.
- Аспекты позволяют пользователям делать эти выборы в любом порядке.
Проблема в том, что, когда на сайте имеется огромный список элементов, и все они могут быть отсортированы по большому количеству параметров фильтрации, тогда потенциал для всех видов причудливых перестановок URL довольно велик, если с самого начала им не управлять должным образом.
Как определить ограненную ловушку навигации
Если ваш веб-сайт предлагает пользователям ряд различных продуктов с множеством различных способов поиска этих предметов, он вполне может быть подвержен ловушке такого типа.
Поиск удлиненных строк URL-адресов, различных повторяющихся фильтрующих тегов и бесконечного цикла в инструменте-обходчике снова является показательным индикатором того, настроен ли ваш сайт для обработки многогранной навигации в SEO-дружественной манере или нет.
Общие метки сортировки, такие как цвет, размер, цена или количество товаров на странице, - это лишь некоторые из множества тегов фильтра, которые могут создавать проблемы для сканера при посещении вашего сайта. Проблемы с обходом вокруг граненой навигации обычно начинают возникать, когда пауку становится очевидно, что можно смешивать, сочетать и / или комбинировать различные типы фильтров.
Например, в приведенном ниже примере с очень популярным ирландским магазином «Сделай сам», если пользователь хочет приобрести краску для предстоящего проекта по оформлению дома, полезно, чтобы он или она могли перейти к нужным параметрам, используя элементы фильтра, такие как цвет. , марка и цена.
Проблема возникает, когда один и тот же пользователь может затем отсортировать этот отфильтрованный результат по количеству продуктов на странице, категории краски, по которой он находится, по максимальной цене, по минимальному диапазону цен и т. Д. И т. Д. Он должен быть способен фильтровать по нескольким важным фильтрам, но не по всем одновременно.
На начальных этапах нашего процесса технического аудита на этом веб-сайте наш сканер был настроен на эмуляцию робота Google с использованием отличных настроек «пользователь-агент» в Screaming Frog.
Вскоре стало очевидным, что ловушка паука испытывалась, что означало, что паук по сути отправлялся по бесконечному, бесконечному циклу через серию фильтров в результате многогранной структуры навигации сайта, что приводило к длинным строкам URL, таким как как 'www.website.ie/kitchen-and-bathroom/kitchen?FilterCategoryID=8399&BrandID=3455&Page=1&PriceHigh=2147483647&PriceLow=0&SortBy=1&q=&ProductsPerPage=9' взбалтывать, только для того, чтобы отослать еще один процесс повторения еще одного процесса через итерацию оставив наш обход в течение нескольких дней, не доведя его до конца.
Мы знали, что это большой сайт, но брови начали подниматься с более чем 20 000 000 просканированных URL!
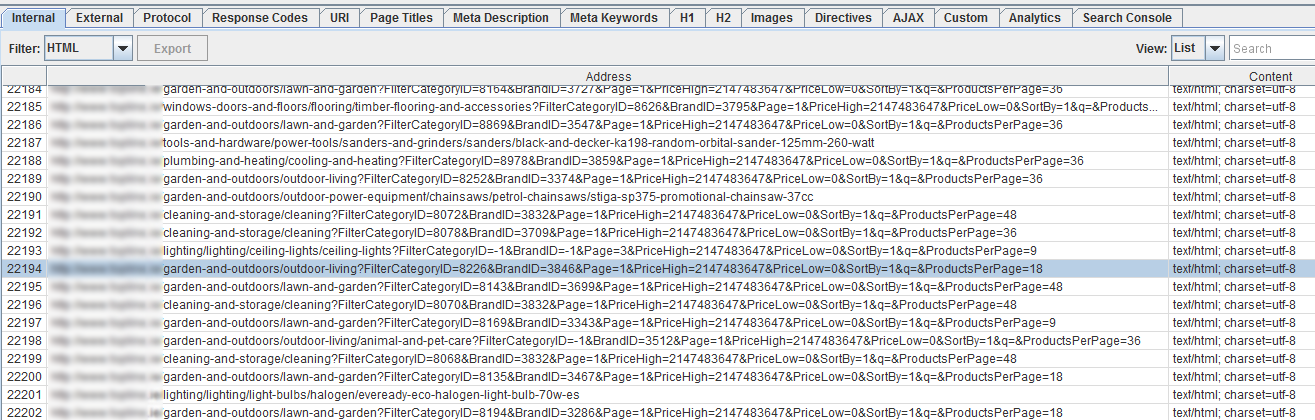
Этот сценарий приводит к потенциально бесконечному (во всяком случае, к миллиардам) количеству перестановок, которые пользователь может настроить, чтобы получить свой ультратонкий результат, который в конечном итоге может быть просто одним очень длинным URL-адресом с одним результатом продукта. отображается на соответствующей веб-странице.
С глубочайшими намерениями UX в этой многогранной навигационной структуре не удалось принять во внимание очень фундаментальный SEO-анализ; «Как же поисковая система извлекает, отображает, анализирует, индексирует и ранжирует эти миллиарды URL-адресов ?!» (ответ - нет, он сдается и движется в какой-то момент, как описано выше в наших аналогиях с бюджетом сканирования!).
Как исправить ограненную ловушку навигации
Опять же, применение исключений к инструменту сканирования будет необходимо только для завершения рассматриваемого сканирования.
Чтобы мы могли исключить незначительные фильтры, не оказывая негативного влияния на способность важных категорий или списков брендов, нам сначала нужно было понять, какие фильтры можно было бы исключить из процесса сканирования, а какие можно было бы постоянно тестировать, чтобы гарантировать что основные целевые страницы, категории и списки товаров не были затронуты.
После периода консультаций с клиентом мы не смогли определить фильтры, относящиеся к контенту, который важен для ранжирования (бренды и категории) и какие излишни в контексте SEO (размер, количество товаров на странице, максимальная цена, минимальная цена и т. д.)
Такое исключение выглядит следующим образом в файле robots.txt сайта:
Disallow: /*PriceHigh.*
Disallow: /*PriceLow.*
Disallow: /*SortBy.*
Disallow: /*ProductsPerPage.*
Disallow: /*searchresults.*
Надежное тестирование требуется с каждым вставленным исключением; исключить слишком много, и некоторые важные списки могут быть сведены на нет из SERP, исключить слишком мало, и проблема может быть решена только частично.
Важно знать, что общий результат этого процесса исключения в конечном итоге будет означать, что будет меньше проиндексированных страниц в Google и других поисковых системах, но что остальные списки будут относиться к более важным страницам на сайте, что дублирование будет уменьшено и, что наиболее важно, что пауки будут лучше позиционированы, чтобы иметь возможность сканировать весь сайт и переориентировать его понимание сайта, без риска для ловушки пауков. Это должно привести к беспроигрышной ситуации как для пауков, так и для веб-мастеров (а впоследствии и владельцев бизнеса).
Лучшая форма защиты от такого рода проблем, связанных с граненой навигацией, - это избегать ее с самого начала! В приведенном выше случае применение рекомендуемых исключений и перестройка мегаменю сайта в HTML5 вместо меню JavaScript помогли приручить эту особую ловушку для пауков, и сайт пожинает плоды с точки зрения органического трафика.
Это не значит, что JS-меню не могут быть эффективными, но их необходимо настроить так, чтобы многогранные слои не заполнялись в динамических строках URL. Больше не всегда лучше, предоставляя пользователям выбор, это всегда хорошо, но наступает момент, когда логика должна преобладать, а пользовательский случай должен строиться вокруг плюсов и минусов наличия еще четырех или пяти фильтрующих объектов, которые не будут действительно влияет на покупку в конце дня.
При использовании JavaScript для обслуживания граненой навигации важно решить, как и чем обслуживать пауков и в каком формате. Вместо того, чтобы просто обслуживать нечитаемые теги JS, мы рекомендуем использовать механизм предварительного рендеринга, такой как Prerender.io чтобы сделать переходы к JS как можно более плавными для предварительно разбирающихся в HTML пауков.
Если исключения и / или перестройки не являются возможными вариантами, то добавление канонических тегов к оскорбительным строкам URL, безусловно, может помочь в части индексации и поможет избежать тонкого контента и потенциальной ответственности сайта от рук Google Panda, но это не так. учтите тот факт, что эти ужасные, удлиненные URL-адреса сначала должны быть просканированы для того, чтобы пауки могли подобрать и соблюдать каноническую директиву.
Итак, надоедливые ловушки для гусеничных машин были удалены; что теперь?!
Теперь, когда вы получили более глубокое понимание потенциальной причины и решения этих четырех основных распространенных ловушек для пауков, мы надеемся, что вы начнете ценить важность использования пауков для повышения общей эффективности вашего сайта с точки зрения SEO.
Есть также еще один довольно интересный случай ловушки пауков, возникающие в результате поиска по ключевым словам это стоит исследовать, если ни одна из вышеперечисленных проблем с ловушкой для пауков не является причиной ваших проблем. Мы еще не сталкивались с этой проблемой ни на одном из сайтов наших клиентов, отсюда и отсутствие подробного освещения; скрестив пальцы, остается дело еще какое-то время!
Google и инструменты поиска в Интернете, чтобы снова отправлять свои XML-карты сайта и разрешать им отображать и индексировать с новыми изменениями на месте. Вы будете удивлены тем, что ваш сайт будет лучше пойман на пост-ловушке! Использование опции Google Fetch and Render на лету при внесении изменений на сайте - верный способ проверить успешность и убедиться, что все хорошо с точки зрения сканирования.
Обеспечение того, чтобы внутренние ссылки хорошо использовались на вашем сайте и чтобы вы создавали свежий контент, - это два надежных способа убедиться, что робот Googlebot понимает, какие области вашего сайта являются наиболее важными для вас в этом новом новом, дружественном для пауков ИА, который вы включен Непрерывные напоминания благодаря разумному использованию контента, ссылок и карт сайта помогут обеспечить правильное формирование приоритета темы.
Наконец, мы рекомендуем встроить процесс, в соответствии с которым у вас есть четко определенный график периодического сканирования SEO для вашего сайта. Как подробно показано выше, в управлении и индексации URL-адресов есть много движущихся частей, поэтому имеет смысл запускать сканирование каждые пару дней, недель или месяцев, в зависимости от размера сайта и частоты изменений. это подвергается. Если вы уже являетесь клиентом Wolfgang, вы можете быть в безопасности, зная, что мы находимся в случае, если ваш сайт когда-либо испытывает гнев ловушки для пауков, но если кто-либо из наших читателей заинтересован в том, чтобы узнать больше о нашем SEO методологии, вы всегда можете связаться с нами и мы с радостью сканируем ваш сайт для вас!
Есть ли у вас какие-либо сумасшедшие проблемы со сканированием или вы видели случай ловушки пауков на вашем собственном сайте или на сайте, которым вы управляете? Если это так, пожалуйста, не будьте незнакомцем в поле для комментариев ниже или в социальных сетях; Мы будем рады услышать ваши отзывы или ответить на любые ваши вопросы, касающиеся укрощения пауков в вашем домене!
Поделиться этой статьей
Что такое бюджет сканирования и почему это важно?Что такое ловушка для пауков и как ее исправить?
Что такое бюджет сканирования и почему это важно?
Что такое ловушка для пауков и как ее исправить?
Если вы лучше разбираетесь в использовании инструментов для сканирования, у вас могут возникнуть острые вопросы, например, «почему это сканирование никогда не закончится?
» или «почему дым исходит от моего нового Lenovo?
Смущены еще?
Ie/kitchen-and-bathroom/kitchen?


